|
|
|||||
|
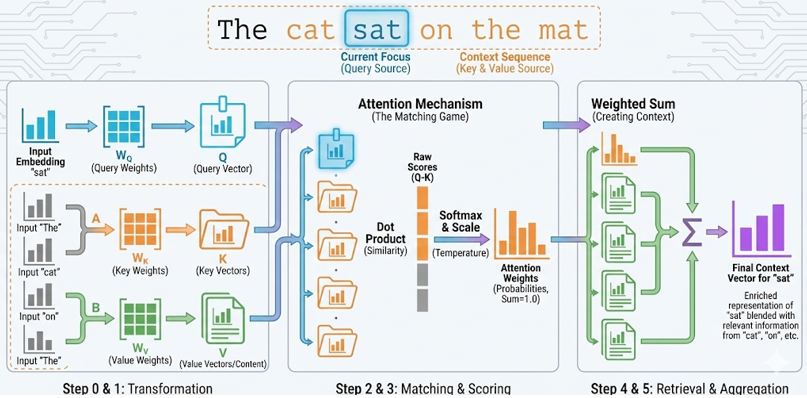
This tutorial explains the Query, Key, Value mechanism in scaled dot-product attention. The goal is to make the data flow obvious: a selected token asks a question with Q, every token offers a searchable label with K, and every token provides retrievable content with V.
The simulation uses small 3-dimensional vectors so every number can be seen. Real Transformer models use much larger vectors, but the mechanism is the same. Sections Mathematical Foundation1. Input tokens become vectorsAssume the sentence is:
Each token is first represented by an input vector X. In a real Transformer, X usually contains token embedding plus positional encoding. In this simulator, each X has only three dimensions so the numbers can be displayed clearly. For the default preset, the simplified input vectors are:
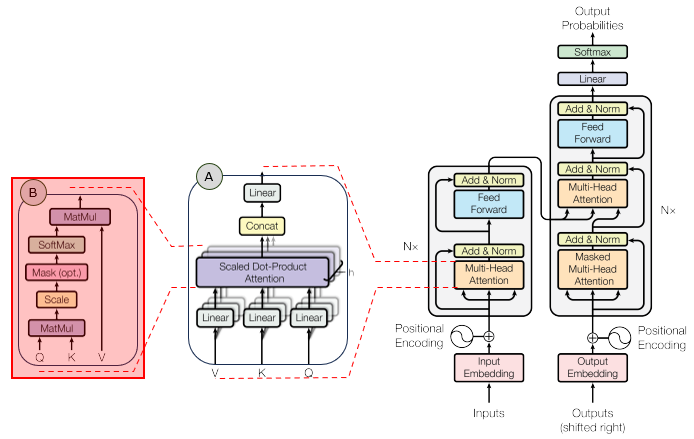
If sat is selected, then 2. Q, K, and V are projections of XTransformer attention does not compare the raw X vectors directly. It first projects X into three different spaces using learned matrices: Q = X WQ K = X WK V = X WVFor the selected token sat, the Query is:
This Query can be interpreted as the question asked by the token sat: "which tokens in this sentence are relevant to me?" Every token also produces a Key. The Key is like a searchable label for that token:
Every token also produces a Value. The Value is the content that will be mixed into the output if that token receives attention:
So Q is the request, K is the matching label, and V is the content to retrieve. 3. Query-Key dot product gives a match scoreNow the Query from sat is compared against every Key: scorei = Q(sat) · KiFor example, the match score between sat's Query and cat's Key is:
The simulator rounds this to
The largest raw score is for sat itself. This means, with these demonstration vectors, the Query generated by sat is most aligned with the Key generated by sat. 4. Scaling and softmax convert scores into weightsRaw dot products can grow large when the vector dimension is large. To control this, scaled dot-product attention divides each score by
For the cat score:
The scaled scores are approximately:
Softmax then converts these scaled scores into positive weights that sum to 1.0: weighti = exp(scaled scorei) / sum(exp(scaled scorej))With temperature = 1.0, the attention weights are approximately:
These values sum to 1.0. The token sat receives the highest weight because it had the highest scaled score. The temperature slider is included only for learning: lower temperature makes the largest score dominate more strongly; higher temperature spreads the weights more evenly. 5. Values are mixed by the weightsThe final attention output is not one of the tokens. It is a weighted mixture of the Value vectors: Output = sum(weighti Vi)For dimension 0, the calculation is:
For dimension 1:
For dimension 2:
The final output vector is approximately:
So Keys decide where to attend, and Values decide what information is retrieved. In this example, sat and mat contribute strongly because their attention weights are relatively large. Complete formulaThe whole operation is summarized as: Attention(Q,K,V) = softmax(QKT / sqrt(dk)) VFor this concrete example, the selected token is sat. Its Query is compared with all Keys, the scores are converted into attention weights, and those weights mix all Value vectors into the final context vector. SimulationThe interactive simulator is below. Use the controls to explore the concepts described above.
1.00
Tokens and input vectors X Attention pipeline Scores and weights
Softmax attention weights Output context vector Formula note Usage Instructions
What To Notice
Parameters
Limitations
|
|||||