|
|
||||||||||||||
|
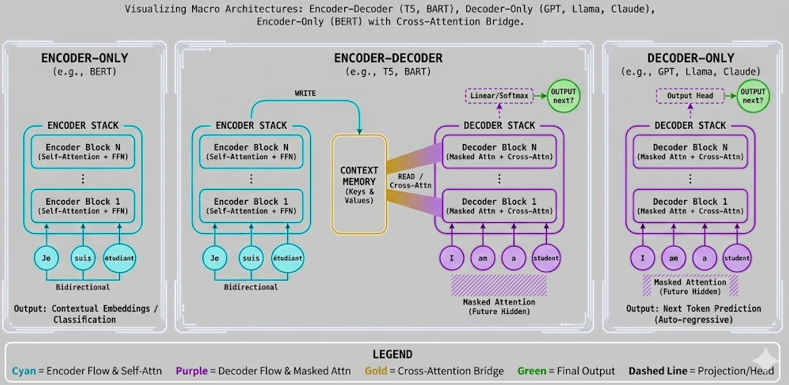
This tutorial zooms out from individual Transformer blocks and shows how complete Transformer architectures are assembled. The key question is: do we need an Encoder, a Decoder, or both?
Sections Mathematical Foundation1. Encoder-only architectureThe encoder receives the full input sequence and uses bidirectional self-attention: H = Encoder(X)For example, with source tokens:
each token can attend to all source tokens:
This is useful for understanding tasks such as classification, search, and embedding generation. 2. Decoder-only architectureThe decoder uses masked self-attention for autoregressive generation: D_t = Decoder(y_0, ..., y_t)For target tokens:
the causal mask allows:
This is the GPT-style architecture for next-token generation. 3. Encoder-decoder architectureEncoder-decoder models use both stacks: H_enc = Encoder(X_src)D_self = MaskedSelfAttention(Y_tgt)C = CrossAttention(Q_dec, K_enc, V_enc)The encoder writes source context into memory. The decoder reads that memory through cross-attention while generating the target sequence. 4. Cross-attention is the bridgeIn cross-attention, the Query comes from the decoder, but Key and Value come from the encoder: CrossAttn = Attention(Q_decoder, K_encoder, V_encoder)For translation, this means:
That is how the decoder can generate English while still looking back at the French source sentence. 5. Prediction headThe decoder output is mapped to vocabulary probabilities: p(next token) = softmax(Linear(D_final))In the simulator example, the largest probability is for SimulationThe interactive simulator is below. Use the controls to explore the concepts described above. Architecture view Encoder Stack
Encoder Block N
Self-Attn + FFN + AddNorm ↑ repeated blocks ↑
Encoder Block 1
bidirectional self-attention Context Memory
K_encoder
V_encoder
WRITE ← Encoder
READ → Decoder
Decoder Stack
Linear / Softmax
predict next token Decoder Block N
Masked Attn + Cross-Attn + FFN ↑ repeated blocks ↑
Decoder Block 1
causal masked self-attention Encoder bidirectional mask
Decoder causal mask
Cross-attention read pattern
Architecture formulas Next-token probabilities Usage Instructions
What To Notice
Parameters
Limitations
|
||||||||||||||