|
|
||
|
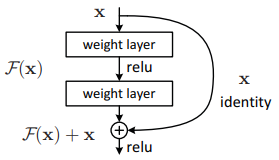
ResNet, short for Residual Network, is a deep convolutional neural network architecture introduced to address the challenges of training very deep networks. Prior to ResNet, increasing network depth often led to a degradation problem, where deeper models paradoxically performed worse, not due to overfitting but because of optimization difficulties. ResNet overcomes this by introducing residual learning, in which layers learn residual functions with reference to the input of the layer rather than unreferenced mappings. This is achieved through shortcut connections that directly pass input signals to later layers, enabling networks to train effectively at unprecedented depths, such as 152 layers on ImageNet, while achieving state-of-the-art performance in image classification, detection, and segmentation tasks. The simplicity and scalability of this design have since made ResNet a foundational architecture in modern deep learning, influencing numerous subsequent models in both computer vision and other AI domains. ArchitectureThe architecture of ResNet is built around the concept of residual learning, where layers are organized into residual blocks that include shortcut, or skip, connections. These connections allow the input of a block to bypass intermediate convolutional layers and be added directly to the block’s output, enabling the network to learn only the residual mapping rather than the entire transformation. This design not only mitigates the vanishing gradient problem but also simplifies the optimization of extremely deep networks. ResNet architectures typically stack these residual blocks in various configurations, such as 18, 34, 50, 101, or 152 layers, with deeper variants adopting a bottleneck structure that uses 1×1 convolutions to reduce computational cost while maintaining representational power. The result is a highly scalable network capable of achieving remarkable accuracy on large-scale image recognition benchmarks. Following diagram shows a residual block used in ResNet. The input value x is sent through two weight layers with ReLU activations applied in between, producing a transformed output F(x). At the same time, the original input x bypasses these layers through an identity shortcut. The outputs of the transformation and the shortcut are added together to form F(x) + x, and a final ReLU activation is applied. This structure allows the network to learn residual functions, making it easier to train very deep models without performance degradation.
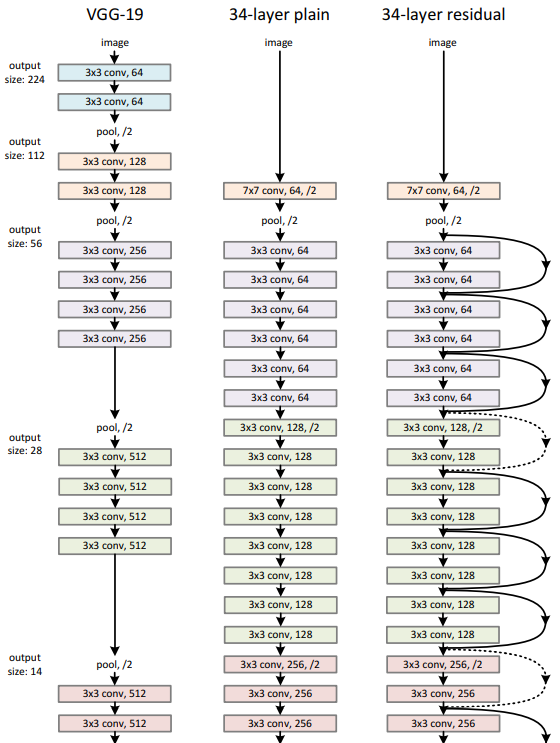
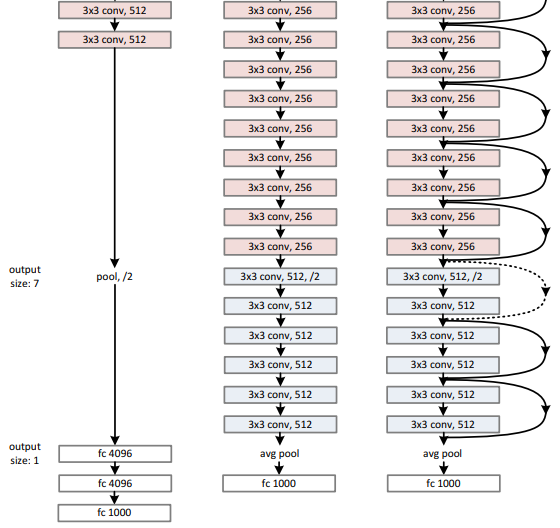
Image Source : Deep Residual Learning for Image Recognition Following diagram compares the architectures of VGG-19, a 34-layer plain convolutional network, and a 34-layer residual network. VGG-19 is structured using repeated 3×3 convolutional layers followed by pooling, gradually reducing the spatial dimensions from 224 to 7 pixels while increasing the number of feature maps from 64 to 512. Its design relies solely on sequential convolution and fully connected layers at the end. The 34-layer plain network introduces deeper stacking of 3×3 convolutions, starting with a 7×7 convolution and pooling, but still lacks shortcut connections. In contrast, the 34-layer residual network retains a similar overall depth and configuration but integrates shortcut connections that bypass sets of convolutional layers, enabling the network to learn residual functions. These shortcuts, depicted as curved arrows, connect the input of each block directly to its output, allowing identity mappings that stabilize training and make very deep networks easier to optimize. Both the plain and residual networks conclude with average pooling and a fully connected layer for classification, whereas VGG-19 ends with three fully connected layers.
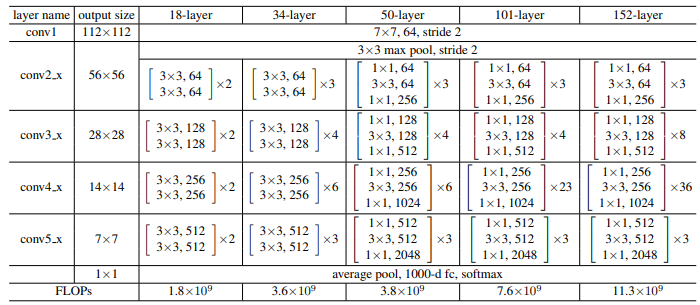
Image Source : Deep Residual Learning for Image Recognition Following table summarizes the configurations of different ResNet variants, ranging from 18 layers to 152 layers. The first row specifies the initial convolution stage, where all models begin with a 7×7 convolution using 64 filters and stride 2, producing an output of 112×112. This is followed by a 3×3 max pooling layer with stride 2. Subsequent rows describe the four main stages of the network, denoted as conv2.x to conv5.x, each reducing spatial resolution and increasing feature dimensions. For the 18-layer and 34-layer networks, every block consists of two 3×3 convolutions, while deeper versions such as 50, 101, and 152 layers use bottleneck blocks that include 1×1, 3×3, and 1×1 convolutions. The table indicates how many such blocks are stacked at each stage, with the number of filters shown in each block and the repetition count denoted by ×2, ×3, ×4, and so on. For example, in the 34-layer model, the conv2.x stage has three blocks of 3×3 convolutions with 64 filters, whereas the 101-layer model uses three bottleneck blocks with filter sizes 64, 64, and 256. The pattern continues through conv3.x, conv4.x, and conv5.x stages, with filters increasing from 128 to 512 for the plain variants and bottleneck expansions from 128 to 2048 in deeper models. After the final stage, all models apply global average pooling followed by a fully connected layer producing 1000 outputs and a softmax for classification. The table also includes the approximate number of floating-point operations for each network, showing how computational complexity increases with depth, from 1.8 billion FLOPs for ResNet-18 up to 11.3 billion FLOPs for ResNet-152.
Image Source : Deep Residual Learning for Image Recognition Main ApplicationsResNet is primarily applied in computer vision tasks, where its residual learning framework enables the training of very deep networks that achieve exceptional accuracy. Originally developed for large-scale image classification on datasets like ImageNet, it quickly became a standard backbone for many vision models. Beyond classification, ResNet architectures are widely used in object detection frameworks such as Faster R-CNN and Mask R-CNN, semantic and instance segmentation tasks, and feature extraction for transfer learning. Its ability to generate rich hierarchical features has also made it valuable in specialized domains such as medical imaging, autonomous driving, and facial recognition, where high precision and robustness are critical. The design principles of ResNet have further influenced numerous modern architectures, ensuring its continued relevance across a broad range of applications. Image classification (e.g., ImageNet, CIFAR)ResNet was originally introduced to tackle large-scale image classification tasks, where models need to assign a single class label to an entire image. By introducing residual connections, ResNet enabled networks with over 100 layers to be trained effectively, setting new performance benchmarks on datasets like ImageNet. On smaller datasets such as CIFAR-10 or CIFAR-100, ResNet demonstrated that deeper architectures could achieve extremely low error rates without overfitting, becoming a standard baseline in image recognition research. Its ability to extract increasingly complex features at greater depths made it a cornerstone for building more sophisticated vision pipelines. Object detection frameworks like Faster R-CNN, Mask R-CNN, and YOLO (ResNet used as backbone)Object detection involves identifying and localizing multiple objects within an image, which requires both feature extraction and region proposal capabilities. ResNet serves as the backbone feature extractor in many state-of-the-art detection frameworks such as Faster R-CNN and Mask R-CNN, replacing earlier architectures like VGG due to its superior representational power and efficiency. In these frameworks, the deep features produced by ResNet layers are fed into region proposal networks and classification heads to accurately detect objects. Even in single-shot detectors like YOLO, ResNet variants have been adapted as backbones to improve accuracy while maintaining reasonable inference speed. Image segmentation tasks, including semantic and instance segmentation (e.g., in medical imaging and autonomous driving)Segmentation tasks require pixel-level classification, dividing an image into meaningful regions or identifying individual objects. ResNet’s deep hierarchical features provide fine-grained contextual information crucial for segmentation networks such as Fully Convolutional Networks (FCNs), U-Net variants, and Mask R-CNN. In medical imaging, this capability allows precise delineation of organs or lesions, while in autonomous driving, it enables the identification of road lanes, pedestrians, and vehicles in real time. The combination of residual learning and encoder-decoder designs has led to highly accurate segmentation models across industries. Face recognition (e.g., ArcFace, FaceNet adaptations)ResNet’s robust feature extraction capabilities have been widely adopted in face recognition systems, where subtle differences in facial features must be captured under varying conditions of lighting, pose, and expression. Architectures such as ArcFace and CosFace often use modified ResNet backbones to generate discriminative face embeddings that can be compared using simple distance metrics. This approach powers large-scale authentication systems, surveillance applications, and even consumer products like smartphone face unlock features. Feature extraction for transfer learning, where pretrained ResNet models are used as a base for other tasksPretrained ResNet models trained on large datasets like ImageNet are commonly reused as feature extractors for a variety of downstream tasks. By leveraging the learned representations from lower and mid-level layers, practitioners can fine-tune only the final layers for tasks such as fine-grained classification, anomaly detection, or cross-domain adaptation. This transfer learning approach dramatically reduces training time and data requirements while still achieving high accuracy, making ResNet one of the most popular backbones for practical machine learning pipelines. Video analysis when extended into 3D convolutions or combined with recurrent networksResNet has also been extended for spatiotemporal analysis by modifying its 2D convolutions to 3D, allowing it to capture motion and temporal dynamics in videos. These 3D ResNets are used for tasks like action recognition, video classification, and gesture detection. Alternatively, ResNet features can be extracted frame-by-frame and processed sequentially using recurrent architectures like LSTMs or Transformers to model temporal dependencies. Such hybrid designs are widely employed in video analytics, sports highlight generation, and surveillance systems that require understanding of both spatial and temporal patterns. LimitationsResNet, despite its groundbreaking impact on deep learning, has several limitations that have become apparent over time. Training extremely deep variants, while theoretically possible, can still be computationally expensive and memory-intensive due to the large number of parameters and high FLOP count. The use of residual connections mitigates vanishing gradients but does not completely eliminate other optimization challenges, such as overfitting on smaller datasets or the need for careful regularization and data augmentation. Additionally, the architecture relies heavily on 3×3 convolutions and fixed-stage designs, which may not be optimal for all tasks, especially when compared to more recent architectures like DenseNet or EfficientNet that achieve similar or better accuracy with fewer parameters. ResNet models also struggle with capturing long-range dependencies in images, which has motivated the shift toward attention-based models such as Vision Transformers. Furthermore, their deployment on resource-constrained devices can be challenging without additional techniques like pruning, quantization, or knowledge distillation to reduce complexity. Here’s a concise bulleted summary of the limitations of ResNet:
Reference :
|
||