|
|
||
|
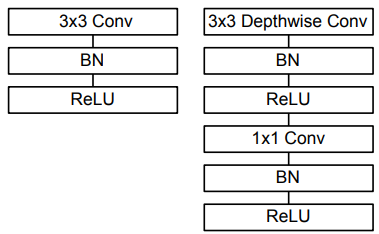
MobileNet is a family of lightweight convolutional neural network (CNN) architectures designed specifically for efficient deployment on mobile and embedded devices. Unlike traditional deep networks that rely on heavy computations and large parameter sizes, MobileNet introduces depthwise separable convolutions to drastically reduce the number of computations and memory footprint without significantly compromising accuracy. This makes it particularly suitable for real-time applications such as image classification, object detection, and segmentation on devices with limited processing power and energy constraints. Its modular design also allows easy adaptation to different trade-offs between speed and accuracy, enabling developers to scale models for various performance needs. ArchitectureThe architecture of MobileNet is built around the concept of depthwise separable convolutions, which factorize a standard convolution into two simpler operations: a depthwise convolution that applies a single filter per input channel, and a pointwise convolution that combines the outputs using 1×1 convolutions. This design significantly reduces both computational complexity and the number of parameters compared to traditional CNNs, while maintaining competitive accuracy. MobileNet also incorporates hyperparameters, such as width multiplier and resolution multiplier, allowing fine-grained control over the trade-off between latency, model size, and accuracy, making it highly flexible for deployment across a wide range of mobile and embedded platforms. The diagram shown below compares the standard convolutional block used in traditional CNNs with the depthwise separable convolution block employed in MobileNet.
By separating spatial filtering (depthwise) and channel mixing (pointwise), this design drastically reduces the number of multiplications and parameters, making MobileNet far more efficient for mobile and embedded applications.
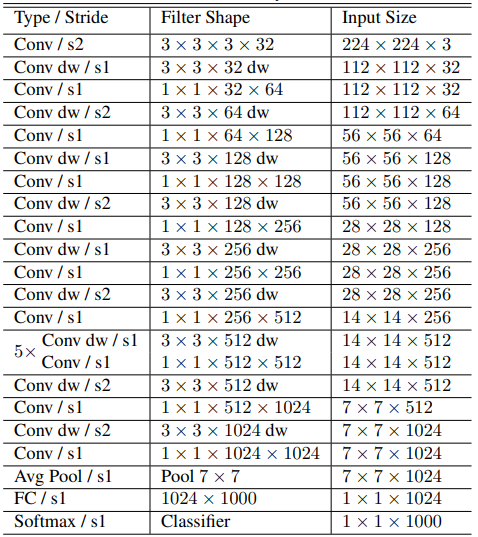
Image Source : MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications The table below represents the layer-by-layer architecture of MobileNet, showing how input data is transformed as it passes through different convolutional stages. The network begins with a standard 3×3 convolution with stride 2 applied to the 224×224×3 input, reducing spatial size to 112×112 while increasing channel depth to 32. It then uses a depthwise 3×3 convolution followed by a pointwise 1×1 convolution, which is the fundamental building block repeated throughout the model. Each depthwise convolution performs spatial filtering independently per channel, while the subsequent 1×1 convolution mixes channel information and adjusts the number of output channels. As the network progresses, spatial resolution gradually decreases (224→112→56→28→14→7) while channel depth increases (32→64→128→256→512→1024). Notably, groups of repeated layers are used for efficiency, such as five consecutive depthwise and pointwise pairs at the 14×14×512 stage. After the final depthwise separable convolutions at 7×7 resolution with 1024 channels, a global average pooling layer reduces the spatial dimension to 1×1×1024, followed by a fully connected layer and softmax classifier to produce the 1000-class output for ImageNet classification. This architecture prioritizes computational efficiency by consistently applying depthwise separable convolutions instead of standard convolutions, resulting in significantly fewer parameters and operations compared to traditional CNNs of similar accuracy.
Source : MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications Here’s a bulleted breakdown of the MobileNet architecture shown in the table:
Main ApplicationsMobileNet is widely used in applications where computational efficiency and low memory usage are critical, making it an ideal backbone for mobile and embedded vision tasks. It serves as the core architecture for image classification tasks on datasets like ImageNet and CIFAR, providing competitive accuracy with significantly fewer parameters than traditional CNNs. Beyond classification, MobileNet is frequently employed as the feature extractor in object detection frameworks such as SSD, Faster R-CNN, and YOLO, as well as in semantic and instance segmentation models used in fields like medical imaging and autonomous driving. Its lightweight design also makes it suitable for real-time face recognition systems and for transfer learning, where pretrained MobileNet models are adapted to specialized tasks. Additionally, with modifications to handle temporal data, it can be extended to video analysis applications that require efficient processing on resource-constrained devices.
LimitationsMobileNet, despite its efficiency and suitability for mobile and embedded devices, has certain limitations that must be considered when choosing it for specific applications. Its lightweight architecture, while reducing computational complexity, often sacrifices some accuracy compared to larger, more complex models like ResNet or EfficientNet, especially when dealing with high-resolution images or tasks requiring fine-grained feature extraction. Additionally, MobileNet can be less effective in scenarios where ample computational resources are available, as its design prioritizes speed and size over absolute performance. Another limitation is its reduced flexibility for scaling to very deep networks, making it less ideal for tasks that benefit from significantly larger receptive fields or multi-scale feature representation. These trade-offs highlight the need to carefully match MobileNet’s strengths to the constraints and goals of the target deployment environment.
Reference :
|
||