HARQ Entity/Process
HARQ(Hybrid ARQ) is pretty complicated process and not easy to understand in very detail, but it would be helpful if you have some big picture of this process. (Describing this process in very detail would not be the scope of this section.)
Let's first think about the terminology. What is H-ARQ ? Why it uses the term "Hybrid" ?
First think about the term ARQ. ARQ stands for Automatic Repeat Request and you would have heard this a lot if you had experience of studying IP communication (I think you can google a lot of tutorials on this, so I would not explain about what is ARQ here). The "H" in HARQ means "Hybrid" which implies that HARQ is a combination of "Something" and "ARQ".
Then what would be the "Something" ? The "Something" is FEC (forward error correction). FEC is also not LTE specific technology and a kind of generic error correction mechanism. So I would like you to google something about FEC.
Followings are the topics that will be described in this page.
- HARQ Structure
- HARQ Process
- HARQ ProcessID Synchronization
HARQ Structure
Following is overall architecture of LTE HARQ entity. Refer to 36.321 5.4.2.1 and 5.4.2.2 for the detailed description of mechanism.
< Overall Architecture of LTE HARQ Entity >
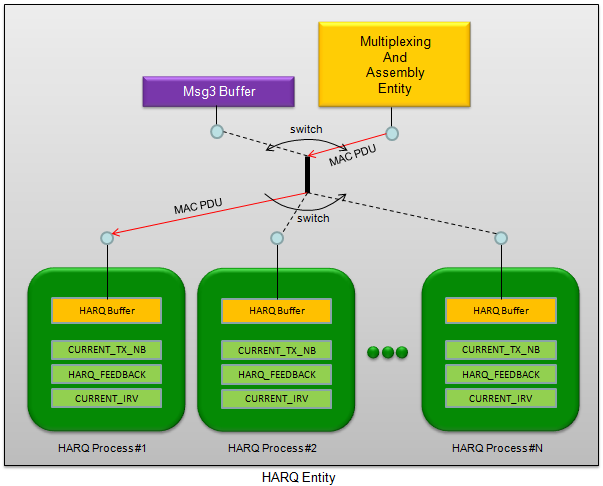
HARQ Process
A little bit different mode of HARQ process is used depending on whether it is for FDD or TDD and whether it is for Uplink and Downlink. But I will talk only about FDD case.
In FDD, we are using 8 HARQ process.
a) it can use the 8 HARQ processes in any order (Asynchronous Process).
b) UE does not know anything about HARQ process information for DL data before it gets it. So Network send these information (Process ID, RV) in PDCCH (DCI, Refer to DCI section of this site).
- UE do "Adaptive retransmission" if it detect DCI 0 with NDI not toggled. (In this case, UE does not care about "HARQ feedback (PHICH)", it retransmit based on DCI 0 information).
- UE do "Non-Adaptive retransmission" if it got "HARQ feedback (PHICH=NACK)" but does not get DCI 0. In this case, UE retransmit the PUSCH in predefined RV and MCS without the information from DCI 0.
a)it have to use the specific process in a specific subframe (Synchronous Process). UE has to use the same HARQ process number every 8 subframes.
b) Since UE have to use specific HARQ process ID at specific subframe, the reciever (eNode B) knows exactly which HARQ process comes when. And eNodeB can also knows about RV because UL Grant (DCI 0) from eNodeB can specify RV using MCS field.
c)it has two mode of operation : Adaptive and Non-Adaptive HARQ
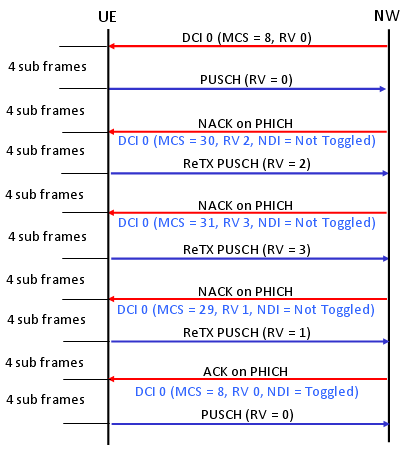
Following is an example of Adative UL HARQ Process (Key idea is that Each UL retransmission uses different RV and the RV is determined by DCI 0).
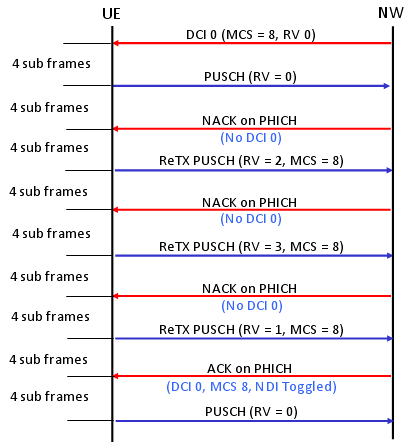
Following is an example of Non Adative UL HARQ Process (Key idea is that Each UL retransmission uses different RV and the RV is determined by predefined sequence specified in TS36.321 "5.4.2.2 HARQ process").
The last but very important question would be "How UE knows if it is supposed to do Adaptive retransmission and Non-Adaptive retransmission ?"
The detailed HARQ Process for Uplink is described in 36.321 - 5.4.2.2 and following is my interpretation of the specification in illustration.
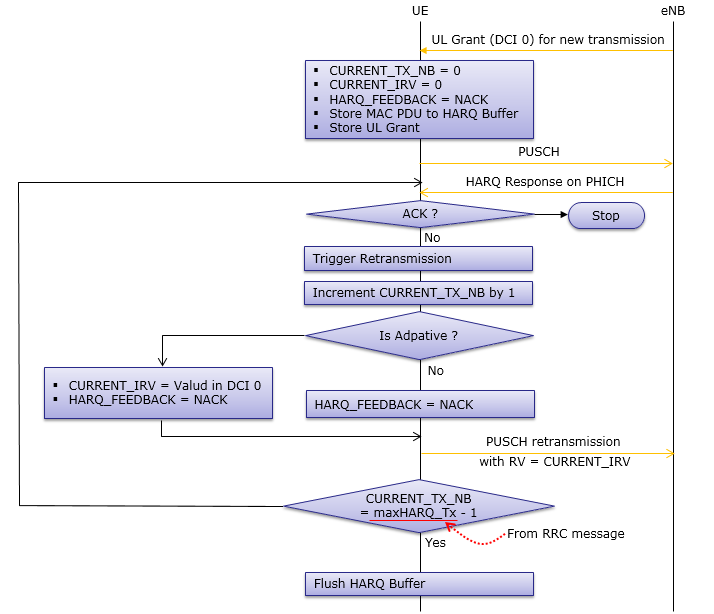
HARQ ProcessID Synchronization
When transfering data via HARQ process, the reciever and transmitter should know 'some information' about Process ID for each of the HARQ process, so that the reciever can successfully keeping each process data without getting them mixed up.
Then is there any specific rule (mathematical formula) to figure out HARQ process ID from SFN and subframe number ?
In LTE, there is no specific formula is defined in the 3GPP specification, but following can be one of the simplest rule in LTE case.
UL HARQ Process ID = (SFN x 10 + subframe) modulo 8
, here we use modulo 8 because LTE use 8 HARQ process
Does the reciever (eNodeB in LTE case) need to know exact HARQ process ID ?
Not Really. As long as eNodeB prepare at least 8 HARQ buffer and store PUSCH for each subframe separately at least for 8 subframe span, there would be no problem of decoding each HARQ data without problem. One possible procedure may go like this :
i) an eNodeB prepare 8 separate HARQ Buffers and let name it as Buf0,Buf1,..,Buf7.
ii) When an eNodeB receives the first PUSCH, it put the PUSCH into the first UL HARQ buffer (Buf0) in the eNodeB.
iii) When the eNodeB receives the second PUSCH, it put the PUSCH into the first UL HARQ buffer (Buf1) in the eNodeB .... Repeat this process
iv) When the eNodeB receives the 8 th PUSCH, it put the PUSCH into the 8th UL HARQ buffer (Buf7) in the eNodeB
v) When the eNodeB receives the 9 th PUSCH, it put the PUSCH into the first UL HARQ buffer (Buf0) in the eNodeB .... Repeat this process.
With this, there may be mismatches between UL HARQ Process ID that is allocated on UE side and the Buf number allocated on the eNodeB receiver buffer, but there would be no problem with decoding the data.
Reference :
[1] HARQ Process Boosts LTE Communications