|
|
||
|
Channel Coding Processing for PUSCHAs far as I know, PUSCH has the most complicated (in many cases confusing) structure. It means you have to spend a lot of time scratching head and being frustrated if you are PHY layer chipset developer or validation/verification engineer working at the area. If you are not the engineer working at that area, don't even think of getting into details -:) But at least it would be good to know the big picture of PUSCH structure and possible combination. Possible Composition of PUSCH can be categorized as below.
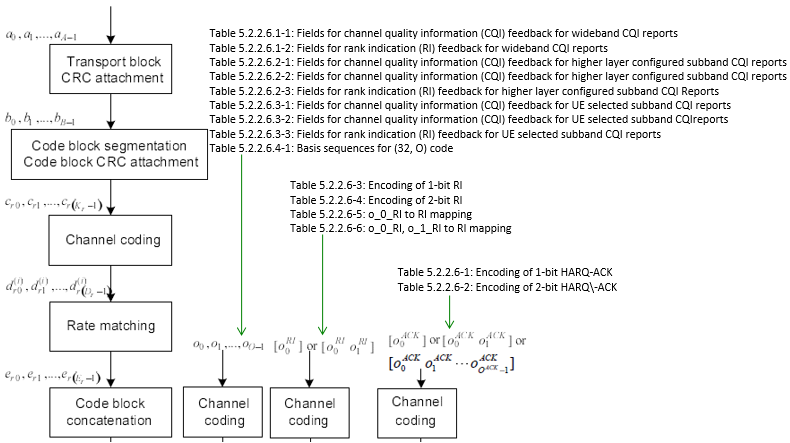
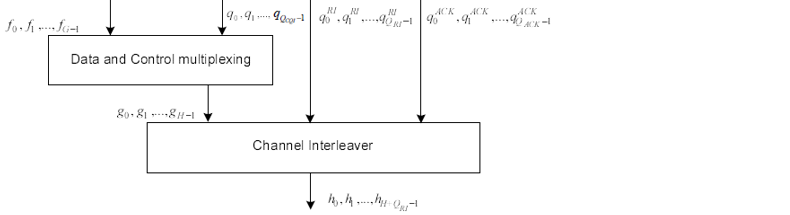
First you have to know exactly at which situation each of these composition is used. (Normally you don't have much issues with troubleshooting the case i)). Once you specified a specific type, go through following procedure one by one as described in 36.212. < 36.212 - Figure 5.2.2-1: Transport channel processing for UL-SCH >
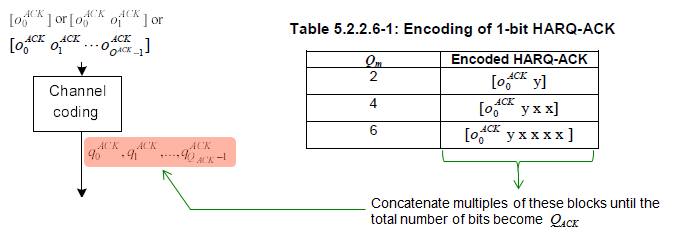
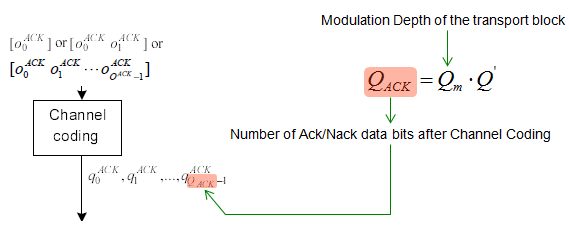
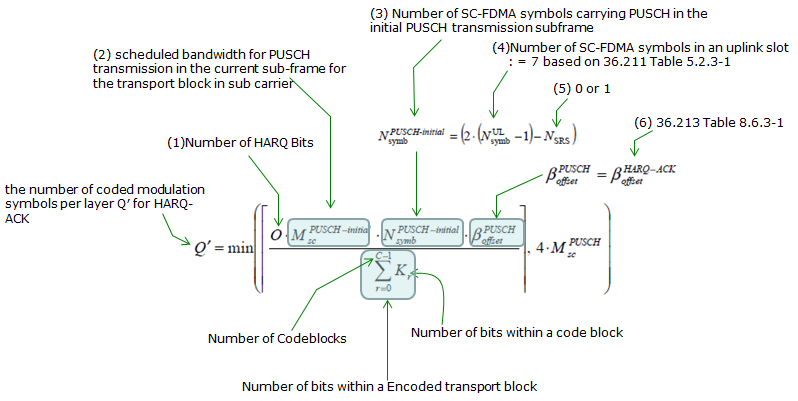
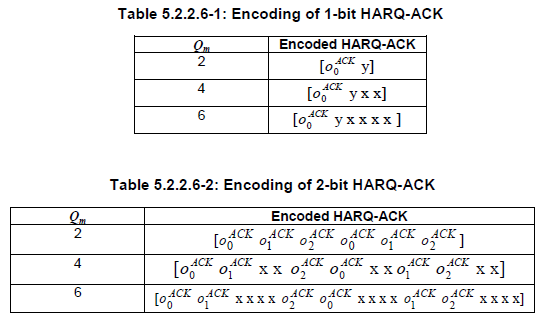
Channel Coding for HARQ ACK
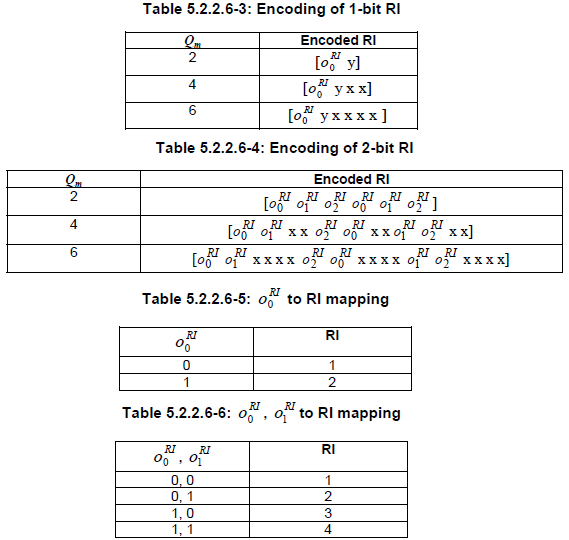
Channel Coding for RI
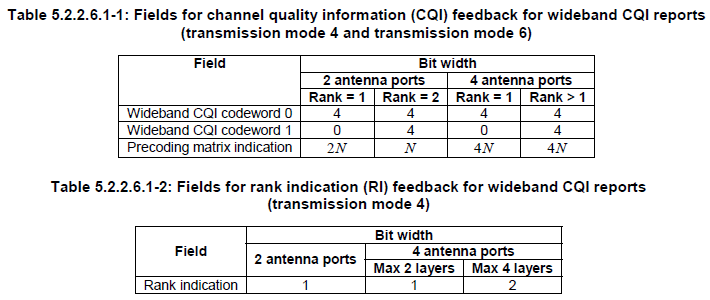
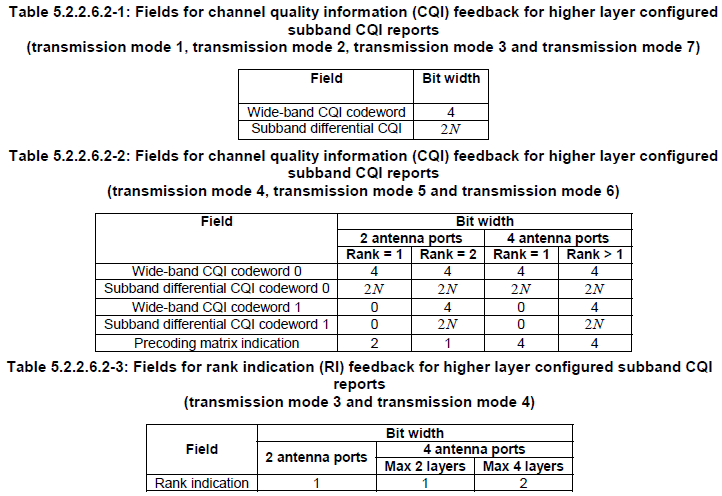
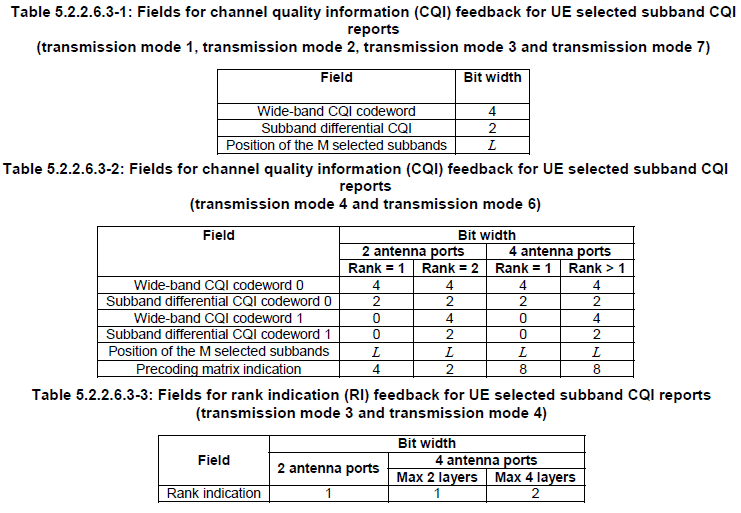
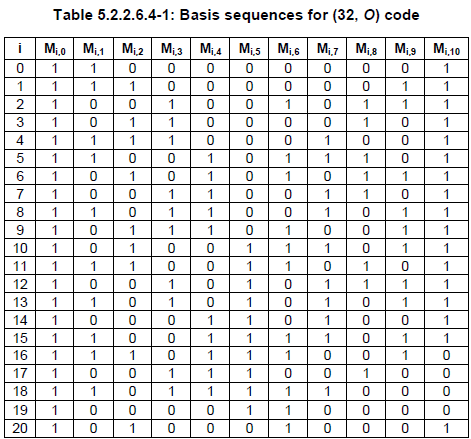
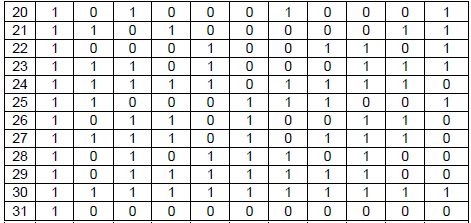
Channel Coding for CQI
|
||