The topics in this note outline the ongoing discussion among companies on how to establish evaluation frameworks, KPIs, and lifecycle management (LCM) principles for AI/ML use cases in 6G. Building on the foundations of 5G NR and 5G-Advanced, participants emphasized the need to broaden the evaluation criteria beyond traditional performance and intermediate metrics to include power consumption, inference latency, training complexity, inter-vendor interoperability, and system overhead. While there was consensus that 5G’s AI/ML frameworks could serve as a starting point, companies debated how much change should be introduced—whether to minimize revisions or embrace a unified, future-proof framework. Proposals also highlighted the importance of ensuring energy efficiency, scalability, and robust data collection mechanisms, while accounting for real-world deployment scenarios and the trade-offs between performance gains and implementation complexity. These summaries capture the early stage of 6GR standardization, where study items are being defined and guiding principles for evaluating AI/ML in 6G are being shaped
- Evaluation and KPIs
- Hybrid ML/non-ML designs
- Selection of AI/ML Use Cases
- Lifecycle Management (LCM) Framework
- Data Collection Framework
- Use Cases
- DMRS Improvement
- CSI Enhancement
- Beam Management Enhancement
- Channel Coding Enhancement
- JSCC / JSCCM Enhancement
- Energy Efficiency Enhancement
- Initial Access Enhancement
- Mobility Enhancement
- Scheduling / Resource Allocation Enhancement
- Power Amplifier (PA) Enhancement
- Modulation / Demodulation Enhancement
Evaluation and KPIs
Evaluation in AI/ML-based 5G and 6G design starts from a simple rule — both model-level and system-level aspects must be measured together. A model may show promising accuracy in isolation, but its real value appears only when it improves network-level outcomes such as throughput, latency, and overhead. Therefore, AI evaluation must include metrics for computational complexity, power consumption, inference delay, and robustness across vendors and configurations. The purpose is to verify not only that the model performs well, but also that it operates efficiently and reliably in practical network conditions.
A clear baseline is essential for fair comparison. Every AI feature should be tested using the same channel models, antenna setups, and NR reference conditions to ensure results are comparable. KPIs should track complexity in operations per bit, memory usage, and energy per bit. They should also measure how well the model generalizes across frequency bands, deployment types, and mobility levels. Equally important is stability—systems must continue to function gracefully even when the AI is disabled or exposed to unfamiliar data.
The evaluation approach should remain flexible but structured. KPI definitions can vary by use case, covering link-level measures such as BLER, EVM, or spectral efficiency when relevant. Inference latency and power efficiency deserve particular focus, since model execution time and energy consumption often determine real-world feasibility. Quantitative limits on inference cost, such as upper bounds in FLOPS or power budgets per operation, help maintain practical balance between performance and efficiency.
In summary, AI/ML evaluation for future networks must follow three guiding ideas: realism, consistency, and transparency. Realism ensures testing reflects deployment conditions. Consistency guarantees fair comparison across systems. Transparency exposes both performance gains and associated trade-offs. This balanced framework allows AI techniques to evolve as an integral part of the cellular standard, complementing conventional mechanisms rather than replacing them.
General Principles - Consider both intermediate (model) KPIs and system-level KPIs.
- Model KPIs include complexity, inference latency, power consumption, memory footprint, and stability.
- System KPIs include throughput, latency, overhead, coverage, and spectral efficiency.
- Align model-level and system-level perspectives to ensure measurable network-level benefit.
- Include AI-specific metrics that capture operational cost such as FLOPS, inference frequency, and compute-to-power ratio.
- Evaluate training latency only for adaptive or continuous learning; exclude it for offline-trained models.
- Ensure robustness under real-world conditions.
- Account for channel variation, device diversity, and mobility.
- Consider data distribution shifts and varying radio environments.
- Define reproducible test conditions that allow direct comparison across evaluations.
- Consider both intermediate (model) KPIs and system-level KPIs.
Evaluation Framework and Guardrails - Establish a unified baseline for fair, apples-to-apples comparison.
- Use shared NR-based reference models, including standardized channel models and MIMO setups.
- Apply identical numerology and traffic profiles for all evaluated schemes.
- Track a balanced set of metrics.
- BLER and spectral efficiency for link-level performance.
- Complexity in operations per bit and memory usage.
- Energy consumption per bit and overall computational load.
- Generalization across frequency bands, deployment types, and mobility scenarios.
- Define guardrails for robustness.
- Ensure graceful degradation when AI is disabled or encounters out-of-distribution data.
- Maintain basic system operation without AI for backward compatibility.
- Encourage evaluation transparency.
- Disclose model assumptions, input distributions, and computation scales.
- Establish a unified baseline for fair, apples-to-apples comparison.
Refined Evaluation Perspectives - Use case–specific KPI selection.
- PHY-layer AI (e.g., channel estimation, detection): emphasize BLER, EVM, and link-level reliability.
- MAC- or RRM-layer AI: focus on throughput gain, latency reduction, and energy savings.
- System-level orchestration: assess inference overhead, control stability, and coordination efficiency.
- Power efficiency as a primary constraint.
- Include both static (model size) and dynamic (inference frequency) power components.
- Quantify inference cost in FLOPS or OPS; define upper bounds such as compute-per-watt targets.
- Evaluate inference latency and deployment feasibility at edge nodes or base stations.
- Combine complexity and generalization metrics to ensure balanced performance across environments.
- Follow standardized KPI structures to maintain consistency across studies.
- Performance, complexity, inference cost, monitoring overhead, and energy efficiency.
- Promote clarity, reproducibility, and scalability in evaluation.
- Encourage sharing of test data, scripts, and baseline results.
- Align reporting format to facilitate cross-vendor validation.
- Use case–specific KPI selection.
Hybrid ML/non-ML designs
The integration of AI and ML into the physical layer requires balance between innovation and interoperability. The goal is to enhance selected processing stages with learned models without breaking the deterministic and testable nature of classical signal chains. This approach treats machine learning as an assistive layer, not a replacement.
Partitioning must be done carefully so that learned blocks add value where statistical adaptation helps, while keeping core signal-processing intact. Each insertion must preserve existing interfaces such as I/Q samples, LLRs, and CSI, allowing legacy and ML-enabled receivers to coexist.
At the transmitter, ML aids can support shaping or precoding choices but must remain compliant with emission masks, linearity, and other RF constraints. Runtime confidence checks and fallback paths are essential to ensure stability and reliability.
Lifecycle management of models is another key aspect. Training, validation, and adaptation must remain observable and reversible. Each model version needs traceability, calibration records, and rollback triggers.
Finally, complexity and power limits define where ML is practical. Lightweight designs should fit within device budgets and deactivate when the gain-to-cost ratio is poor. Verification and interoperability procedures must be clearly defined so mixed ML/non-ML systems can operate together.
In summary, the purpose is to insert learning where it helps, contain it where it risks instability, and ensure that all gains are measurable, reversible, and compatible with standard 5G/6G PHY frameworks.
Partition points & interfaces - Insert lightweight learned blocks where they add value while keeping classical signal-processing as the backbone.
- Receiver-side candidates: channel estimation, equalization/interference cancellation, soft-demapping/LLR refinement, decoder assist.
- Preserve standard interfaces (I/Q samples, LLRs, CSI) to remain interoperable with non-ML pipelines.
Transmitter-side pragmatics - Use ML assists without violating RF constraints or complicating specs.
- Shaping/precoding assistants (e.g., distribution matching hints, precoder selection aid) with fixed, spec-compliant outputs.
- Honor emission masks, EVM/MPR limits; avoid model-driven behaviors that change outward PHY characteristics.
Confidence gating & fallback - Make ML optional at runtime with deterministic safety nets.
- Expose confidence/health indicators and thresholds to gate ML decisions per TTI or per burst.
- Immediate rollback to classical algorithms on drift, KPI regressions, or OOD detection.
Training & adaptation strategy - Keep lifecycle disciplined and observable.
- Offline pretraining with field calibration; optional on-device/federated updates via LCM hooks and versioning.
- Define validity windows, rollback conditions, and audit trails for each deployed model.
Complexity & power budgeting - Fit designs to device tiers and traffic profiles.
- Set ops/bit, memory, and latency budgets per class (IoT → eMBB) and enforce duty-cycling of learned blocks.
- Deactivate ML assists under low-SNR/low-gain regimes where benefits don’t justify power cost.
Data handling & privacy - Build trust and minimize risk.
- Minimize training/inference data; prefer on-device features or anonymized summaries with operator visibility.
- Log model decisions/events for explainability without exposing user payloads.
Verification & testability - Prove gains against stable baselines.
- Use deterministic test vectors and NR-like baselines for A/B comparisons under agreed channels/MIMO setups.
- Track BLER/SE/latency/energy and OOD robustness as release criteria.
Interop & capability signaling - Make mixed fleets work seamlessly.
- Advertise ML capability, model IDs, and supported fallback modes through lightweight signaling.
- Ensure graceful operation with non-ML peers and across software versions.
Selection of AI/ML Use Cases
The selection of AI/ML use cases in 5G and 6G standardization follows a disciplined and pragmatic approach. Each company emphasizes measurable performance gains while maintaining compatibility with existing architectures and ensuring implementation feasibility. The focus is not only on improving throughput or accuracy but also on balancing complexity, interoperability, and deployment practicality.
Vendors and operators use different but converging criteria. Most require that AI-based solutions outperform classical methods under fair conditions while keeping fallback paths available. Complexity, signaling impact, and energy efficiency are now treated as critical evaluation dimensions, not afterthoughts.
Another emerging trend is the need for explainability and runtime assurance. Proposals must demonstrate stability across datasets and scenarios, with performance metrics tied to real system KPIs such as CQI accuracy, beam index reliability, and HARQ success rates.
Ultimately, the goal is to identify AI/ML use cases that can bring clear, standardized value—whether as 5G-Advanced extensions or as enablers of new 6G features—while keeping devices affordable, networks interoperable, and operations sustainable.
Performance and Practicality - Prioritize use cases that show measurable performance improvement over existing non-AI solutions under standardized conditions.
- Ensure that any gain in throughput, reliability, or latency is achieved without excessive increase in implementation complexity or signaling overhead.
- Maintain full interoperability with legacy and non-ML processing pipelines.
Fallback and Robustness - Require deterministic fallback mechanisms to conventional algorithms in case of model drift or degraded confidence.
- Support runtime switching between AI and non-AI modes without service interruption or KPI instability.
- Design AI components as optional assists, not mandatory dependencies, ensuring consistent system operation across deployments.
Complexity–Performance Trade-off - Balance performance improvement against computational cost, memory footprint, and latency impact.
- Quantify trade-offs using end-to-end metrics such as throughput, BLER, or spectral efficiency, alongside resource utilization and power draw.
- Establish thresholds beyond which AI complexity no longer provides net system benefit.
Classification and Evolution Path - Classify use cases into three categories: 5G-Advanced supported, 5G-Advanced extensions, and new-generation (6G) features.
- Align new AI/ML proposals with existing specification boundaries to minimize standard impact and ensure forward compatibility.
- Provide clear migration paths for experimental features toward standardized adoption in later releases.
Device Efficiency and Resource Control - Optimize AI design for device tiers by constraining processing load, memory use, and inference frequency.
- Minimize on-device training; prefer centralized or federated updates with strict version control.
- Ensure energy efficiency and maintain UE affordability by bounding AI-specific hardware or power requirements.
Sustainability and Service Enablement - Consider long-term sustainability, including power consumption, thermal impact, and hardware longevity.
- Encourage use cases that not only enhance performance but also enable new services or user experiences.
- Promote reuse of trained models across scenarios to reduce development overhead and carbon footprint.
Measurement and Reporting - Quantify each use case by reporting operational parameters such as OPS count, inference rate, and power consumption.
- Track both intermediate KPIs (e.g., SNR, NMSE, LLR accuracy) and ultimate KPIs (e.g., throughput, latency, reliability).
- Analyze model generalization across diverse datasets, mobility profiles, and channel conditions.
Verification and Validation - Require reproducible simulation or field results demonstrating AI gains over standard receivers or transmitters.
- Evaluate feasibility for UE implementation, including hardware cost, inference latency, and energy budget.
- Use controlled A/B comparisons under agreed test environments to verify robustness and scalability.
Runtime Assurance and Trust - Continuously monitor inference quality at runtime using indicators such as CQI deviation, beam index drift, and HARQ failure trends.
- Define standardized “AI-Trust Indicators” to reflect model confidence and operational health.
- Integrate these indicators into scheduling and link-adaptation logic for real-time performance protection.
Lifecycle Management (LCM) Framework
Lifecycle Management of AI/ML in 6G builds on the foundation established in 5G NR but extends it toward a more adaptive, transparent, and intelligent framework. The 5G design mainly supported one-directional model handling, where training occurred offline and deployment followed fixed control flows. For 6G, this approach becomes too restrictive. As AI moves deeper into the radio interface and network intelligence layers, models must be continuously updated, distributed, and validated in real time. This transition raises the key design question — whether to preserve backward compatibility with minimal changes or to enable a complete redesign that supports a wider range of learning and deployment scenarios.
The new framework must integrate data and model management, dynamic adaptation to network and UE conditions, and advanced training paradigms such as online learning, federated learning, and meta-learning. It also needs to address hardware and energy efficiency, as AI workloads begin to coexist with conventional signal processing at the base station and UE. Managing inference latency, processing cost, and memory utilization becomes as important as achieving learning accuracy. The LCM design should therefore establish a clear link between algorithmic intelligence and system-level performance, ensuring that learning-driven features remain predictable and explainable in operation.
A well-defined lifecycle is essential. Every model must follow a consistent process—training, activation, monitoring, and rollback. Each stage should include operator visibility and control, allowing explainability and accountability within the network. Rollback mechanisms must guarantee deterministic fallback to non-AI baselines whenever models deviate from expected behavior. Standardized signaling—such as model identifiers, validity scopes, and rollback triggers—should be integrated through PHY/MAC hooks. Continuous monitoring of KPIs like BLER, latency, and power efficiency enables automatic fallback or retraining decisions when thresholds are violated.
Ultimately, the 6G LCM framework aims to create a unified environment for AI/ML management—scalable, secure, and interoperable across vendors and layers. It should enable multi-node learning, site-specific adaptation, and shared model state while preserving trust through transparent auditing. Rather than treating AI as an external add-on, 6G positions lifecycle management as the core mechanism that allows learning systems to evolve safely, efficiently, and collaboratively within the cellular standard.
General Themes - Use the 5G NR LCM framework as the initial foundation, but reevaluate its design philosophy for 6G.
- 5G LCM mainly supported single-direction control and limited AI functionalities.
- 6G requires a flexible, bidirectional framework that enables continuous coordination between network and device intelligence.
- Debate remains on whether to preserve backward compatibility or to allow major architectural redesign.
- Minimal changes reduce integration complexity but restrict innovation.
- A redesigned approach allows unified model management, dynamic learning, and long-term scalability.
- Enhance the framework with full-lifecycle AI/ML support.
- Integrated data and model management, including collection, labeling, versioning, and synchronization.
- Dynamic adaptation to network and UE conditions such as mobility, channel variation, and load.
- Support for online, federated, and meta-learning modes enabling real-time and distributed updates.
- Optimized AI/ML processing units with reduced inference latency and memory footprint.
- Power-efficiency mechanisms balancing intelligence with energy constraints.
- Establish a unified model management architecture.
- Define consistent procedures for model creation, activation, suspension, and deactivation.
- Enable version tracking and compatibility across network elements such as gNB, UE, and edge nodes.
- Support multi-cell and multi-site operations through common model identification schemes.
- Embed explainability, transparency, and auditability in every lifecycle stage to ensure operator trust.
- Use the 5G NR LCM framework as the initial foundation, but reevaluate its design philosophy for 6G.
Model Lifecycle and Fallback - Define the complete lifecycle for each AI/ML model — training, activation, monitoring, and rollback.
- Training may occur offline, online, or via federated aggregation depending on context.
- Activation must verify model integrity, compatibility, and validity before use.
- Monitoring continuously evaluates model behavior against target KPIs.
- Rollback guarantees deterministic fallback to non-AI baselines when performance degrades.
- Implement standardized signaling hooks for lifecycle operations.
- Signal model identifiers, version indices, and validity scopes through PHY/MAC layers.
- Include rollback triggers and reactivation policies in control signaling.
- Support asynchronous updates across distributed network elements without service interruption.
- Continuously monitor KPIs such as BLER, latency, throughput, and energy efficiency.
- Define adaptive thresholds and anomaly detection for out-of-distribution behavior.
- Automatically trigger fallback or retraining when KPI violations occur.
- Ensure operator visibility and audit functions.
- Provide readable summaries describing model updates, expected gain, and risk level.
- Maintain logs and version history for traceability and regulatory compliance.
- Expose dashboards for monitoring model health and lifecycle decisions.
- Define the complete lifecycle for each AI/ML model — training, activation, monitoring, and rollback.
Framework Evolution Directions - Move toward a unified and flexible LCM framework covering multiple AI/ML functions and network domains.
- Support modular plug-in structures for AI tasks like channel prediction, beam management, and RRM.
- Enable shared compute and memory units for concurrent models to improve efficiency.
- Introduce meta-learning and adaptive memory mechanisms.
- Allow rapid model reconfiguration or retraining based on local context and mobility patterns.
- Maintain persistent memory structures to retain useful learning context between sessions.
- Ensure scalability, security, and interoperability across network layers.
- Support hierarchical learning between edge, RAN, and core domains.
- Protect model integrity and data privacy during transfer or aggregation.
- Promote cross-vendor consistency through standard formats and control interfaces.
- Adopt the principle of graceful evolution.
- Reuse proven aspects of the 5G NR framework while removing constraints that limit innovation.
- Focus on a clean, transparent, and future-proof design for sustainable AI integration into 6G.
- Move toward a unified and flexible LCM framework covering multiple AI/ML functions and network domains.
Data Collection Framework
Data collection plays a central role in enabling AI/ML-driven intelligence within the 6G system. While the 5G NR framework already supports certain measurement and reporting mechanisms, it was not originally designed with large-scale learning feedback loops in mind. For 6G, the objective is to create a unified, future-proof data collection framework that can serve multiple AI/ML functions across layers and working groups. This involves balancing two goals — ensuring broad applicability across use cases while maintaining flexibility for domain-specific customization.
The discussion focuses on whether the framework should remain an extension of existing NR measurement and reporting procedures or evolve into a more general-purpose, learning-oriented data management plane. Such a plane would handle the collection, pre-processing, and exchange of AI-relevant data (e.g., channel state, interference, mobility patterns, resource usage, and hardware-level statistics) in a consistent and interoperable manner. Defining a clear boundary between use case–specific collection (for example, CSI feedback for channel prediction) and general-purpose collection (e.g., cross-layer learning datasets) is essential to avoid overlap and ensure clean coordination among RAN1, RAN2, and SA groups.
From a design perspective, the framework must ensure scalability, privacy, and efficiency. Collected data should be structured with standardized content and formats, supporting both real-time and historical analysis. It must also integrate seamlessly with the AI/ML lifecycle management framework, allowing models to be trained, validated, and updated based on continuously gathered field data. This requires alignment across working groups so that the mechanisms for collection, storage, and signaling remain coherent throughout the overall 6G architecture.
In summary, the 6G data collection framework aims to move beyond traditional measurement reporting. It should evolve into a unified infrastructure that feeds learning systems while maintaining transparency, interoperability, and system stability. RAN1’s task is to define the scope, structure, and signaling mechanisms of this framework, ensuring that it supports diverse AI/ML use cases while remaining compatible with existing NR principles and forward-looking 6G designs.
Discussion Points - Enhance the existing NR-based data collection framework to make it future-proof and unified across all working groups.
- Design a flexible structure that can evolve alongside AI/ML integration without requiring frequent redefinition.
- Ensure interoperability between RAN, Core, and Service layers through common data semantics and signaling procedures.
- Clarify the scope and purpose of data collection.
- Differentiate between use case–specific collection (e.g., CSI, beam metrics, scheduling decisions) and general-purpose collection (e.g., system KPIs, mobility statistics, energy usage).
- Define data ownership, access control, and retention policies to support both centralized and distributed learning architectures.
- Consider establishing a new AI/ML data management plane.
- Provide a unified mechanism for collecting, labeling, and exchanging AI-relevant data across network functions and nodes.
- Include interfaces for data pre-processing, anonymization, aggregation, and compression to reduce overhead.
- Support adaptive collection frequency based on model feedback or system conditions.
- Ensure that the framework remains aligned with the AI/ML Lifecycle Management (LCM) design.
- Data collected under this framework should directly feed model training, monitoring, and rollback mechanisms.
- Define consistency between collection triggers, LCM state transitions, and model update procedures.
- Identify RAN1 responsibilities and cross-group dependencies.
- RAN1 to specify the technical content, structure, and signaling format for AI/ML data collection.
- Findings and requirements from RAN1 may influence framework modifications in RAN2, RAN3, and SA groups.
- Promote inter-group coordination to maintain a coherent end-to-end data handling architecture.
- Include key measurement and performance monitoring aspects.
- Extend existing NR measurement categories (e.g., DL/UL reference signals, interference, and mobility) to include AI-relevant metrics such as inference load or processing delay.
- Enable data capture at multiple layers — PHY, MAC, and hardware (e.g., CPU/GPU utilization) — for holistic analysis.
- Support both real-time and historical data usage.
- Allow time-series data collection for model retraining, anomaly detection, and trend analysis.
- Provide standardized storage and export interfaces for external analytics and benchmarking.
- Ensure scalability, privacy, and efficiency.
- Incorporate mechanisms for data filtering, sampling, and encryption to protect user information and reduce overhead.
- Optimize reporting intervals and data granularity based on network load and AI task priority.
- Enhance the existing NR-based data collection framework to make it future-proof and unified across all working groups.
Conclusion - RAN1 to study the detailed content, structure, and format of data collection per use case.
- Define which data elements are required for each AI/ML function and how they should be represented.
- Identify signaling extensions or configuration parameters needed for efficient collection and reporting.
- Evaluate potential reuse of existing NR measurement mechanisms where appropriate to maintain backward compatibility.
- RAN1 to study the detailed content, structure, and format of data collection per use case.
Additional Considerations - Clarify the purpose of data collection within the AI/ML workflow.
- Distinguish data used for training, inference, or performance monitoring.
- Define the control interface for enabling or disabling collection based on model or system states.
- Promote synchronization with other ongoing 6G studies.
- Align with the LCM and model management framework to avoid duplication of signaling or storage functions.
- Coordinate with physical-layer studies to determine the role of CSI, measurement pilots, and channel statistics in AI-driven data collection.
- Maintain flexibility for future extensions.
- Allow framework updates as new AI/ML use cases emerge beyond the initial study phase.
- Provide hooks for future integration of distributed data sharing or cross-domain analytics.
- Clarify the purpose of data collection within the AI/ML workflow.
Use Cases
AI/ML integration in 6G is expected to extend across the physical layer, control plane, and system operation, transforming how wireless networks sense, predict, and adapt to their environment. Each use case represents a concrete point where intelligence can replace static configuration or rigid signaling with dynamic, context-aware behavior. The objective is not to replace existing NR mechanisms but to enhance them through learning-based prediction, compression, and optimization—always within well-defined control and lifecycle boundaries.
The use cases studied in this phase collectively define the design space for AI-enabled RAN functions. They span channel acquisition, beam management, coding, sensing, and energy optimization—each requiring new signaling interfaces, trust indicators, and lifecycle management (LCM) hooks for activation, monitoring, and rollback. At the PHY and MAC layers, AI primarily aims to reduce overhead, improve robustness, and minimize UE complexity, while at the system level, it enhances energy efficiency, mobility handling, and joint communication–sensing functionality.
Key directions include smarter channel representation and feedback (AI-assisted CSI acquisition), receiver-side intelligence to reduce pilot overhead, predictive beam and mobility management for faster adaptation, and energy-aware scheduling for sustainable operation. AI-based source–channel joint coding and integrated sensing further blur traditional boundaries between communication and perception. Across all these areas, explainability and fallback remain essential—each AI-assisted function must expose its validity, confidence, and rollback conditions to ensure stable operation and cross-vendor interoperability.
In essence, these 6G AI/ML use cases illustrate the gradual shift from static configuration to intelligent adaptation. They define where and how learning can be embedded in the radio system to improve performance while maintaining transparency, control, and compatibility with established NR principles.
The AI/ML use cases described in this section are derived from ongoing discussions, technical contributions, and study items presented in 3GPP RAN1. These use cases represent potential areas of exploration and are intended solely to illustrate the range of AI/ML concepts currently being evaluated for future 6G systems. Their inclusion here does not imply endorsement, approval, or prioritization by 3GPP, nor does it mean that these techniques will be adopted, standardized, or realized in any final 6G specification. The ultimate set of features and mechanisms standardized for 6G will depend on future study results, consensus within the working groups, cross-layer alignment, feasibility assessments, and system-level evaluations conducted throughout the standardization process.
Therefore, the content in this section should be interpreted as a summary of candidate technical directions and potential use cases under study, rather than a definitive roadmap of features that 6G will ultimately support. Readers should view these descriptions as exploratory and subject to change as the 3GPP standardization process progresses.
DMRS Improvement
In 6G, the role of DMRS becomes a critical bottleneck because the system must support far larger antenna arrays, higher MU-MIMO orders, and more frequent channel tracking demands than in 5G. The conventional DMRS structure was originally designed to be fully orthogonal to data and to scale only up to a certain number of ports, so the overhead in 5G NR already reaches almost thirty percent in some configurations. When this structure is extended to the massive port counts envisioned for 6G, the overhead grows to an unsustainable level and directly limits spectral efficiency. At the same time, operation in upper-mid bands and FR3 requires more frequent and more accurate channel estimation due to faster channel variation, mobility, and positioning requirements, which further increases the demand for reference signals. In this situation, simply adding more DMRS symbols or ports is no longer a practical solution, so 6G needs a way to preserve channel-estimation accuracy while using much fewer pilot resources. This is where AI/ML fits naturally. With an AI-based receiver, the UE can infer the full time-frequency channel structure from sparse DMRS patterns, or even from DMRS partially superimposed onto data, without relying on dense orthogonal pilots. This allows 6G to reduce DMRS density in the time domain, the frequency domain, or the spatial domain, while still maintaining performance at a level comparable to or better than legacy interpolation-based methods. Therefore, AI/ML for DMRS is not a decorative feature but a necessary evolution: it enables high-layer MIMO operation, preserves spectral efficiency under extreme antenna scaling, and provides the flexibility required for new 6G use cases that demand fast, precise, and resource-efficient channel tracking.
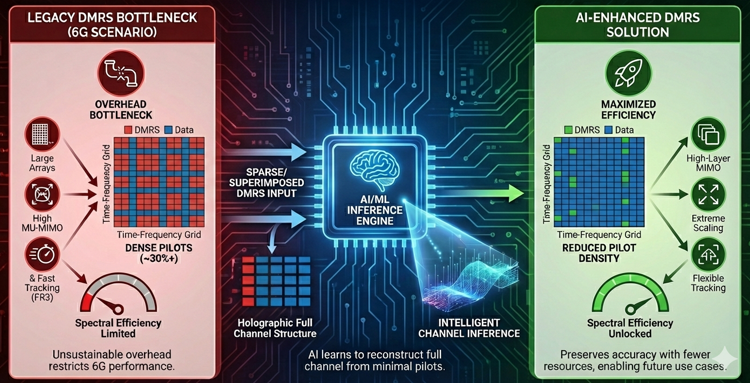
Motivation
The main reason AI/ML becomes necessary for DMRS improvement in 6G is that the traditional receivers are no longer capable of extracting accurate channel information when DMRS density is aggressively reduced. In 5G, the channel estimation process depends heavily on orthogonal pilots and structured interpolation across time and frequency. This approach only works well when enough pilots are available and the channel changes slowly enough for linear or MMSE-based interpolation to remain valid. In 6G, none of these assumptions hold. The number of DMRS ports increases dramatically with massive MIMO, the channel coherence shrinks in upper-mid and FR3 bands, and multi-layer scheduling creates irregular pilot patterns that break the neat structure assumed by legacy estimation algorithms. If we try to reduce DMRS overhead using conventional methods, the channel estimation error increases sharply and leads to large BLER and throughput degradation. AI/ML provides a fundamentally different capability: it can learn the underlying structure of the propagation environment and the statistical relationship between sparse pilots and the full channel matrix. This allows the receiver to infer dense channel information from sparse DMRS, or even from superimposed DMRS embedded inside data, something impossible for classical LS/MMSE-based receivers. As a result, AI/ML becomes the only practical way to maintain channel-estimation accuracy while reducing DMRS density in the time, frequency, and spatial domains. It enables high-port, high-layer 6G operation without letting pilot overhead dominate the resource grid, and therefore is an essential component of achieving 6G-level spectral efficiency under massive MIMO and fast-varying channels.
In 5G, channel estimation relies on: - Dense and orthogonal DMRS patterns
- Structured interpolation across time and frequency
- LS/MMSE assumptions that require slow channel variation
These assumptions break down in 6G because: - DMRS ports increase dramatically with massive MIMO
- Channel coherence shrinks in upper-mid and FR3 bands
- Multi-layer scheduling produces irregular pilot patterns
Reducing DMRS density under these conditions leads to: - Sharp increase in channel estimation error
- BLER spikes
- Throughput degradation
AI/ML becomes necessary because it can: - Learn the mapping between sparse DMRS and the full channel
- Capture non-linear and long-range dependencies traditional methods miss
- Infer dense channel information from sparse or irregular pilots
- Separate DMRS and data when they are superimposed
As a result: - AI/ML is the only practical way to reduce DMRS overhead without losing performance
- 6G can support high-port, high-layer operation without pilot overhead dominating the grid
- AI/ML becomes a core enabler for 6G-level spectral efficiency under fast-varying channels
Methodology
In 6G, the major methodologies for improving DMRS with AI/ML fall into a few clear categories. The first one is AI-based channel estimation using sparse DMRS. Here, only a fraction of the DMRS resources are transmitted in time or frequency, but a neural model—typically a CNN, DnCNN, MLP-Mixer, or Transformer—reconstructs the full channel matrix from these sparse samples. This allows the system to cut DMRS overhead in half or even to one-third while keeping the channel-estimation quality close to or better than conventional MMSE-based processing. The second methodology is AI-based joint channel estimation and equalization, where the receiver does not follow the NR pipeline of “DMRS → CE(Chennel Estimation) → EQ(Equalization) → LLR”. Instead, a neural network takes the received DMRS and data together and directly outputs either equalized symbols or soft bits. This approach handles non-linearities, interference, and sparse pilots much better than the traditional cascaded algorithms. The third methodology is superimposed DMRS (SIP) with AI separation, where DMRS is embedded inside the data REs instead of using dedicated pilot REs. A CNN or similar model then learns to disentangle pilots and data jointly, enabling an entirely different overhead-free reference-signal structure that only becomes practical with ML-based receivers. A fourth important methodology is AI-assisted DMRS pattern design, where models help evaluate or optimize time-domain, frequency-domain, and spatial-domain DMRS distribution, especially when the number of ports grows to 64 or beyond. This allows flexible pilot structures that are not feasible under the strict orthogonality constraints of the NR design. A fifth direction is model-based and hybrid AI receivers, where partial domain knowledge (e.g., LS channel estimates, noise variance, or DMRS structure) is combined with neural refinement to improve robustness. This includes model-driven networks that start from an LS/MMSE baseline and use AI layers to refine the estimates. Finally, there is transformer-based channel prediction and interpolation, which learns temporal and spatial correlation structures and generalizes better to mobility and FR3 environments. All these methodologies share the same intention: reduce the dependence on dense, orthogonal DMRS while achieving channel-estimation quality that satisfies 6G’s massive MIMO and high-mobility requirements.
AI-based channel estimation using sparse DMRS - Only a fraction of DMRS resources are transmitted in time or frequency
- Neural models such as CNN, DnCNN, MLP-Mixer, and Transformer reconstruct the full channel
- DMRS overhead can be reduced to one-half or one-third while maintaining estimation quality
AI-based joint channel estimation and equalization - Receiver bypasses the NR pipeline of “DMRS → CE → EQ → LLR”
- Neural networks directly output equalized symbols or soft bits
- Better handling of non-linearity, interference, and sparse pilots
Superimposed DMRS (SIP) with AI-based separation - DMRS is embedded inside data REs instead of occupying dedicated REs
- CNN or similar models jointly disentangle overlapping pilot and data signals
- Enables almost overhead-free pilot structures impractical for classical receivers
AI-assisted DMRS pattern design - Models evaluate or optimize time-domain, frequency-domain, and spatial-domain DMRS placement
- Supports large port counts (e.g., 64+) without strict orthogonality requirements
- Allows flexible pilot patterns not feasible in NR design
Model-based and hybrid AI receivers - Combine domain knowledge (LS/MMSE estimates, noise variance, DMRS structure) with neural refinement
- Improve robustness while reducing model complexity
- Include model-driven networks that refine traditional channel estimates using AI layers
Transformer-based channel prediction and interpolation - Learn temporal and spatial correlation structures effectively
- Generalize better under mobility and FR3 environments
- Support reduced DMRS density while preserving channel accuracy
Overall goal - Reduce reliance on dense, orthogonal DMRS
- Maintain high-quality channel estimation suitable for 6G massive MIMO and high mobility
Models
For DMRS-related use cases in 6G, several neural network models are being explored because each model captures a different structure of the wireless channel when only sparse or superimposed DMRS is available. CNN-based models form the core approach since they naturally handle the two-dimensional time-frequency structure of the received grid and can refine LS/MMSE estimates into higher-quality channel maps even when the DMRS pattern is very sparse. Residual networks such as ResNet build on this idea and stabilize deeper architectures, allowing the receiver to learn more complex relationships between scattered DMRS and the full channel response. Transformer models are also highlighted because their attention mechanism captures long-range dependencies across time and frequency, so they are effective in reconstructing channels for mobility scenarios or for DMRS patterns that break the regular NR structure. Recurrent models such as Bi-LSTM focus on temporal evolution and are useful when the channel changes quickly across OFDM symbols, especially in high-mobility or high-frequency cases where DMRS cannot be dense enough. MLP-Mixer models are applied mainly in superimposed-DMRS receivers because they process channel features by mixing information across time and frequency without relying on convolution, which helps separate overlapping pilot and data components. Fully connected networks also appear in lighter modules inside the receiver pipeline where local decisions or refinements are needed. Overall, these model families form the toolbox used in 6G to recover accurate channel information from reduced DMRS overhead, superimposed pilots, or flexible pilot structures that traditional receivers cannot handle.
CNN-based models - Handle the 2D time–frequency structure of the received grid naturally
- Refine LS/MMSE estimates into higher-quality channel maps
- Remain effective even when the DMRS pattern is very sparse
Residual networks (ResNet) - Stabilize deeper architectures for complex channel relationships
- Improve reconstruction when DMRS positions are scattered
- Extend CNN capability without vanishing-gradient issues
Transformer models - Use attention to capture long-range time-frequency dependencies
- Effective for mobility scenarios and fast channel variation
- Handle irregular DMRS patterns that break NR’s structured assumptions
Recurrent models (Bi-LSTM) - Track temporal channel evolution across OFDM symbols
- Useful for high-mobility or FR3 channels with quickly varying conditions
- Compensate for the lack of dense DMRS in the time domain
MLP-Mixer models - Mix information across time and frequency without convolution
- Well suited for superimposed-DMRS scenarios
- Help disentangle overlapping pilot and data components
Fully connected networks (FCN) - Used for lighter processing blocks inside the receiver
- Provide local refinement or auxiliary decision modules
- Offer low-complexity components for hybrid AI receivers
Overall toolbox - Enable channel recovery from sparse or superimposed DMRS
- Support flexible pilot structures not compatible with classical receivers
- Form the core set of architectures used to reduce DMRS overhead in 6G
Challenges
When applying AI/ML to DMRS-related functions in 6G, several challenges naturally arise due to the gap between theoretical AI models and practical radio implementations. The first difficulty comes from the highly variable nature of wireless channels, since models trained on specific environments may not generalize well when the propagation condition, mobility pattern, or interference structure changes. This means an AI receiver that performs well in one scenario may degrade sharply in another unless continuous retraining or domain adaptation is supported. Another challenge is the tight processing budget on the UE side; DMRS-based channel estimation must run within strict latency and power constraints, but many of the proposed neural models—especially Transformers and deep CNNs—can require substantial computational resources and memory that may exceed what a handheld device can support. Data availability is another issue: high-quality labeled datasets for sparse DMRS or superimposed-DMRS scenarios are difficult to obtain, and synthetic data may not fully capture real-world impairments such as phase noise, IQ imbalance, hardware nonlinearity, or multi-cell interference. Stability and reliability also become critical, because even a small inference error or unexpected output can propagate into equalization, demodulation, and HARQ, causing sudden BLER spikes that operators cannot tolerate. Finally, integrating AI-based DMRS schemes with existing air-interface procedures, such as HARQ timing, RS coexistence, mobility, and codebook operation, requires careful specification work to ensure backward compatibility and predictable behavior. Together, these points illustrate that while AI/ML enables aggressive DMRS reduction and new pilot structures, it also introduces new layers of complexity that must be addressed before 6G systems can safely depend on AI receivers in commercial deployments.
Generalization challenges - Wireless channels vary widely across environments
- Models trained under specific conditions may not generalize to different mobility, propagation, or interference scenarios
- AI receivers may require continuous retraining or domain adaptation to remain reliable
UE processing and latency constraints - DMRS-based channel estimation must execute within tight timing budgets
- Transformers and deep CNNs may exceed UE power and memory limitations
- Real-time inference must fit into strict PHY-layer scheduling boundaries
Data availability and realism - Labeled datasets for sparse or superimposed DMRS are difficult to obtain
- Synthetic data may not fully capture real impairments (phase noise, IQ imbalance, hardware nonlinearity, multi-cell interference)
- Training-data mismatch can degrade channel-estimation accuracy in field conditions
Stability and reliability risks - Small inference errors can propagate into equalization, demodulation, and HARQ
- AI receivers may cause sudden BLER spikes under unexpected channel conditions
- Operators require predictable behavior, which is difficult with non-deterministic models
Interworking with existing air-interface procedures - AI-based DMRS schemes must align with HARQ timing, RS coexistence, and mobility procedures
- Integration with codebook operation and CSI procedures requires careful standardization
- Backward compatibility must be preserved despite new pilot structures and receiver behavior
Overall complexity - AI/ML allows aggressive DMRS reduction and flexible pilot structures
- But it introduces additional complexity that must be resolved before commercial deployment
CSI Enhancement
In 6G, CSI enhancement becomes a central use case because the radio interface must support extremely large antenna arrays, wide bandwidths, and diverse propagation environments that make CSI acquisition both more expensive and more critical than in 5G. As systems move into upper-mid bands and FR3, the spatial and temporal channel structure becomes more irregular and highly frequency selective, requiring richer and more accurate CSI to maintain beamforming gain and enable high-order MU-MIMO. However, generating such CSI with the existing NR approach would require dense CSI-RS configurations and large uplink CSI feedback, which leads to excessive overhead on both downlink and uplink. This tension between increasing CSI accuracy requirements and the need to maintain spectral efficiency forces 6G to revisit how CSI is obtained, represented, and fed back. AI/ML provides a new mechanism to discover structure in sparsely sampled CSI and to compress or reconstruct CSI far more efficiently than linear or codebook-based methods. As a result, CSI enhancement through AI/ML becomes a foundational capability for enabling scalable massive MIMO, robust mobility, and energy-efficient operation in 6G.
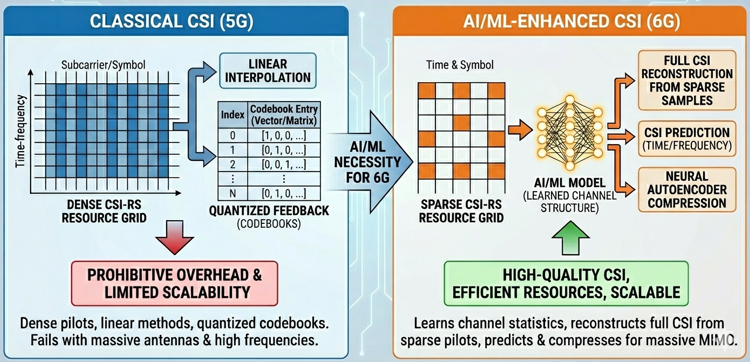
Motivation
The main reason AI/ML becomes necessary for CSI enhancement is that classical CSI acquisition and feedback mechanisms do not scale with 6G requirements. In 5G, CSI relies on relatively dense CSI-RS patterns, linear interpolation, and quantized feedback via predefined codebooks. These mechanisms assume moderate antenna counts, stable channel statistics, and limited feedback budgets. In 6G, these assumptions no longer hold. The number of antennas and layers increases dramatically, the channel coherence shrinks at higher frequencies, and multi-TRP operation creates spatial inconsistencies that make the existing CSI structures inefficient. If CSI-RS density or feedback precision is increased using traditional methods, overhead quickly becomes prohibitive in both DL and UL directions. AI/ML provides a new alternative by learning the statistical structure of the channel, enabling reconstruction of full CSI matrices from sparse RS samples, predicting CSI across time or frequency, and compressing CSI using neural autoencoders instead of fixed codebooks. This allows 6G to obtain richer CSI while using far fewer radio resources. As a result, AI/ML becomes the only practical way to deliver high-quality CSI for 6G massive MIMO without overwhelming the resource grid or feedback channel.
-
Traditional CSI acquisition relies on: - Dense CSI-RS transmission
- Linear or MMSE interpolation at the receiver
- Quantized feedback using predefined codebooks
-
These assumptions fail in 6G because: - Antenna counts and MU-MIMO layers scale much higher than NR design limits
- Channel coherence shrinks in upper-mid band and FR3
- Multi-TRP and multi-panel deployments create complex spatial patterns
- Codebook-based feedback becomes too coarse or too large to be practical
-
Classical CSI approaches under these conditions lead to: - High DL overhead from dense CSI-RS
- High UL overhead for CSI feedback
- Loss of beamforming gain due to inaccurate or outdated CSI
-
AI/ML becomes necessary because it can: - Reconstruct full CSI from sparse CSI-RS samples
- Predict CSI across time, frequency, or even between bands
- Compress CSI using autoencoders or JSCC/JSCCM schemes
- Infer CSI without relying strictly on fixed codebook quantization
-
As a result: - 6G obtains richer CSI with far less overhead
- Massive MIMO and multi-TRP operation become scalable
- Beam management, mobility, and link adaptation become more robust
Methodology
In 6G, the major methodologies for CSI enhancement with AI/ML can be grouped into a few key categories. The first category is AI-based CSI reconstruction from sparse RS, where only a subset of CSI-RS or other reference signals is transmitted, and a neural model reconstructs the full CSI tensor over time, frequency, and space. This directly reduces downlink RS overhead while keeping CSI quality close to or better than conventional interpolation. The second category is AI-based CSI compression and feedback, where encoder–decoder architectures or JSCC/JSCCM schemes map high-dimensional CSI into compact latent representations that can be fed back with fewer bits than legacy codebooks. A third category is temporal and frequency-domain CSI prediction, where models exploit channel correlation to predict future or unmeasured CSI, reducing the need for frequent RS transmission or large-band measurements. Cross-band and cross-link CSI inference form a fourth category, in which CSI observed on one band, panel, or link is used to infer CSI on another, enabling more efficient multi-band and multi-TRP operation. Finally, there are AI-assisted CSI codebook and report design schemes, where models help tailor feedback structures, quantization strategies, or reporting modes to specific deployment conditions. All these methodologies target the same goal: delivering sufficiently accurate CSI for 6G massive MIMO while minimizing RS and feedback overhead.
-
AI-based CSI reconstruction from sparse RS - Transmit only a subset of CSI-RS or other pilot resources
- Use neural models to reconstruct full time–frequency–space CSI
- Reduce DL RS overhead while maintaining CSI quality
-
AI-based CSI compression and feedback - Use encoder–decoder networks or JSCC/JSCCM for CSI compression
- Map high-dimensional CSI to compact latent representations
- Reduce UL feedback bits compared to fixed codebook schemes
-
Temporal and frequency-domain CSI prediction - Exploit temporal correlation to predict future CSI samples
- Exploit frequency correlation to fill unmeasured subbands
- Lower RS density by predicting CSI rather than always measuring it
-
Cross-band and cross-link CSI inference - Infer CSI of one band from CSI measured on another band
- Leverage multi-panel or multi-TRP observations to infer missing CSI
- Enable more efficient multi-band and multi-link operation
-
AI-assisted CSI codebook and report design - Use AI/ML to design or adapt CSI codebooks and reporting formats
- Tune quantization strategies and feedback granularity to deployment
- Balance CSI accuracy and feedback overhead based on learned statistics
-
Overall goal - Provide high-quality CSI for 6G massive MIMO and mobility
- Minimize RS and feedback overhead on both DL and UL
Models
For CSI enhancement in 6G, several neural network families are considered because each captures a different aspect of the CSI structure across time, frequency, and space. Transformer-based models are particularly attractive for CSI reconstruction and prediction, since attention mechanisms can capture long-range dependencies and irregular sampling patterns in the time–frequency grid. CNNs and ResNet-style architectures are used to exploit local correlations and spatial patterns, making them suitable for 2D or 3D CSI tensors derived from RS measurements. Autoencoder architectures, including convolutional and Transformer-based variants, play a central role in CSI compression and JSCC/JSCCM, where encoder and decoder jointly learn compact latent spaces that preserve the most useful channel features. Recurrent models such as LSTM or Bi-LSTM are applied to sequences of CSI snapshots to track temporal evolution, especially in mobility scenarios. Lighter MLP or MLP-Mixer models can be used in scenarios where complexity and latency must be tightly constrained, or as refinement modules on top of more structured estimators. Together, these model families provide a flexible toolbox to meet different complexity, latency, and performance targets in CSI enhancement.
-
Transformer-based models - Capture long-range time–frequency–space dependencies via attention
- Handle irregular or sparse RS patterns naturally
- Well suited for CSI reconstruction, prediction, and JSCC/JSCCM
-
CNN and ResNet architectures - Exploit local structure in 2D or 3D CSI tensors
- Refine coarse CSI estimates into higher-quality maps
- Provide a balance between performance and complexity
-
Autoencoder-based architectures - Jointly learn CSI compression and reconstruction
- Serve as the backbone for neural CSI feedback schemes
- Enable JSCC/JSCCM over noisy links
-
Recurrent models (LSTM / Bi-LSTM) - Model CSI as a time series over frames or slots
- Track temporal evolution under mobility
- Support predictive CSI updates between explicit measurements
-
MLP / MLP-Mixer and lightweight networks - Provide lower-complexity options for UE-side inference
- Act as refinement or adaptation modules on top of baseline estimates
- Useful where strict latency or power constraints apply
-
Overall toolbox - Supports different CSI tasks: reconstruction, compression, prediction, and inference
- Allows tuning of performance–complexity tradeoffs per deployment
Challenges
Applying AI/ML to CSI enhancement also introduces a number of challenges that must be resolved before large-scale deployment. Generalization is a primary concern: models trained on specific channel models or deployment scenarios may not perform well when propagation, interference, or mobility patterns differ significantly, requiring mechanisms for continual learning or periodic retraining. Complexity and latency are also critical, especially on the UE side, where CSI reconstruction, compression, or decoding must be completed within tight timing and power budgets. Training data quality and realism pose another challenge, as simulator-generated datasets may not capture all hardware impairments or multi-cell interference present in the field. Robustness and reliability are vital, since erroneous CSI reconstruction or compression can degrade beamforming, scheduling, and link adaptation, leading to throughput loss or instability. Finally, integrating AI-based CSI procedures into existing specification frameworks involves careful design of LCM, capability signaling, fallback behaviors, and coexistence with legacy codebook-based CSI reporting. These challenges highlight that while AI/ML makes richer and more efficient CSI handling possible, substantial engineering and standardization work is needed to ensure safe and predictable operation in 6G networks.
-
Generalization and robustness - Models may overfit to specific channel models or deployments
- Performance can degrade under unseen propagation or interference conditions
- Requires strategies for continual learning, adaptation, or robust training
-
Complexity and latency constraints - CSI reconstruction and compression must meet strict timing budgets
- UE-side computation and memory are limited
- Encoder–decoder pipelines must be efficient on both UL and DL paths
-
Training data and realism - High-quality labeled CSI datasets are difficult to obtain
- Simulation-based data may miss hardware and multi-cell impairments
- Training–deployment mismatch can harm field performance
-
Impact on beamforming and link adaptation - Errors in CSI reconstruction can reduce beamforming gain
- Unreliable CSI feedback can disrupt scheduling and MCS selection
- Operators require predictable performance under all supported modes
-
Specification and interworking issues - Need clear LCM procedures for CSI-related AI models
- Must define capability signaling, fallback modes, and coexistence with legacy CSI
- Standardization must balance flexibility with interoperability
-
Overall complexity - AI/ML enables richer and more efficient CSI handling
- But adds design, implementation, and validation complexity that must be managed
Beam Management Enhancement
In 6G, beam management becomes one of the most demanding procedures because the system must support extremely large antenna arrays, fine-grained beam directions, and multi-TRP operation across diverse frequency ranges including FR3. Compared to 5G, where beams are moderately wide and updated periodically, 6G beams are narrower, more numerous, and must be updated far more frequently to maintain link reliability in high-mobility or blockage-prone environments. Traditional NR beam management relies heavily on periodic beam sweeping, CSI-RS/SSB–based measurements, and fixed beam refinement procedures. These mechanisms become inefficient as the number of beams per TRP grows and the number of TRPs per UE increases. This results in large control overhead, increased power consumption, and slow reaction time. AI/ML enables 6G to infer optimal beams from partial measurements, predict beam transitions before they occur, and reduce the need for exhaustive sweeping. As a result, AI-based beam management becomes a fundamental enabler for scalable massive MIMO, robust mobility, and energy-efficient operation.
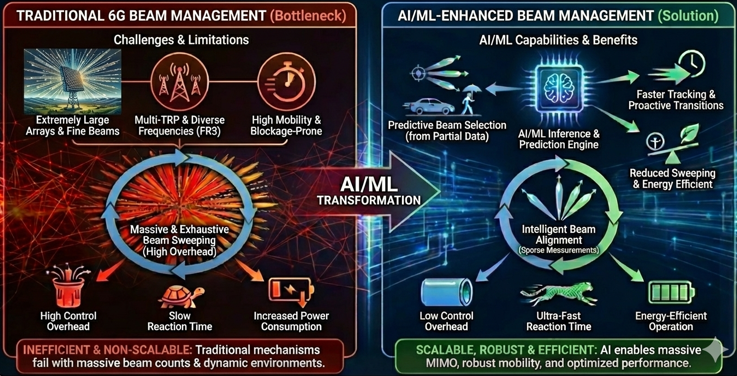
Motivation
Beam management in 6G requires faster tracking, higher beam resolution, and multi-TRP coordination, all of which significantly increase overhead if classical NR mechanisms are extended directly. SSB sweeping becomes too costly with large beam counts, CSI-RS–based refinement requires too many resources, and feedback of beam quality becomes inefficient as directional granularity increases. Blockage, mobility, and dynamic environments further exacerbate these limitations. AI/ML offers the ability to predict beam direction, infer beam quality from sparse measurements, and select beams without exhaustively testing all candidates. This allows 6G to maintain beam alignment while dramatically reducing sweeping and reporting overhead.
Traditional beam management relies on: - SSB sweeping across all candidate beams
- CSI-RS–based beam refinement and measurements
- Codebook-based beam selection and reporting
These assumptions break down in 6G because: - Beam counts increase significantly with large arrays
- Beams become narrower, requiring more frequent updates
- Multi-TRP and multi-panel operation introduces spatial inconsistency
- Mobility and blockage require predictive rather than reactive tracking
Classical methods under these conditions lead to: - Excessive SSB/CSI-RS overhead
- Slow reaction time during mobility
- Frequent misalignment and beam failure events
AI/ML becomes necessary because it can: - Predict beam transitions using historical CSI/beam patterns
- Select optimal beams from sparse RS or partial measurements
- Infer beam direction from cross-band or cross-TRP information
- Reduce sweeping by ranking beams before explicit testing
As a result: - 6G reduces sweeping overhead and improves mobility robustness
- Beam failure recovery becomes faster and more reliable
- Multi-TRP beam coordination becomes scalable
Methodology
6G beam management enhancement with AI/ML follows several major approaches. The first is beam prediction, where models learn temporal beam evolution and identify the next expected best beam, reducing reliance on reactive sweeping. The second is beam quality inference using sparse CSI-RS or partial RF observations, allowing the UE or gNB to estimate beam performance without measuring every direction. A third methodology is cross-frequency and cross-TRP beam inference, where beams learned at one band or TRP help infer beams at another, enabling more efficient multi-band operation. Another key method is AI-assisted beam sweeping reduction, where models rank beams before sweeping so that only a small subset must be tested. Beam refinement and fine-tracking also benefit from AI-enhanced interpolation of angular domain information. Together, these methodologies enable scalable and responsive beam management in complex 6G deployments.
Beam prediction - Predict next-best beam from historical CSI or beam index sequences
- Reduce reliance on reactive beam sweeping
- Improve robustness under mobility and blockage
Beam quality inference from sparse measurements - Use limited CSI-RS or partial RF samples to estimate beam quality
- Reduce CSI-RS density and UE measurement burden
- Infer beam ranking without explicit measurement of all beams
Cross-frequency / cross-TRP beam inference - Use beams learned at one frequency to infer beams at another
- Fuse multi-TRP information to infer global optimal beams
- Support multi-band and multi-TRP deployments efficiently
AI-assisted beam sweeping reduction - Rank beams before sweeping using prediction or inference models
- Reduce the number of beams requiring explicit testing
- Lower overhead and speed up beam alignment
AI-enhanced beam refinement and tracking - Interpolate or reconstruct angular domain information
- Improve continuous fine tracking for narrow beams
- Enhance beam stability under dynamic environments
Overall goal - Enable scalable, predictive, and low-overhead beam management
- Support massive MIMO and multi-TRP operation in 6G
Models
Several neural model families are explored for beam management in 6G. Sequence-based models such as LSTM, GRU, and Transformers are used for beam prediction by learning temporal evolution patterns. CNN-based models extract beam-domain or angular-domain features from sparse CSI-RS or RF samples. Autoencoder-type architectures compress and reconstruct beamspace information for ranking or inference tasks. Graph neural networks (GNNs) appear in multi-TRP and multi-panel inference tasks where spatial relationships matter. Lightweight MLP-based models serve as efficient ranking or scoring modules suitable for UE-side inference. Together these models cover prediction, inference, ranking, and refinement functions required for AI-enhanced beam management.
Sequence models (LSTM / GRU / Transformers) - Learn temporal beam evolution
- Predict next or future beam indices
- Improve mobility robustness
CNN-based models - Extract spatial/angular features from CSI-RS grids
- Infer beam quality from sparse measurements
- Support fast beam ranking
Autoencoders - Compress and reconstruct beamspace representations
- Reduce UE feedback or processing requirements
- Enable denoising and beam refinement
Graph neural networks - Model multi-TRP, multi-panel spatial relationships
- Infer beams across distributed antennas
- Improve global beam coordination
Lightweight MLP/MLP-Mixer models - Provide fast beam scoring and ranking
- Suitable for UE-side inference under power limits
Overall toolbox - Supports prediction, inference, scoring, and refinement
- Adaptable to complexity constraints across UE/gNB
Challenges
Applying AI/ML to beam management poses several challenges. First, generalization is difficult because beam patterns depend heavily on deployment, TRP geometry, environment, and frequency band; models trained in one setting may perform poorly in another. Second, real-time beam prediction and inference must run under strict timing constraints, especially on the UE side. Third, high-quality datasets capturing mobility, blockage, and multi-TRP geometry are difficult to collect, and simulated datasets may lack realism. Fourth, erroneous beam prediction or ranking can lead to beam misalignment, triggering beam failures and throughput collapse. Finally, integrating AI-driven beam management with existing SSB/CSI-RS-based procedures requires clear LCM handling, fallback behavior, and coexistence with legacy NR mechanisms.
Generalization challenges - Beam patterns vary with environment, TRP layout, and frequency
- Models may not transfer well across deployments
- Requires domain adaptation or robust training
Timing and complexity constraints - Beam prediction must meet tight PHY timing
- UE compute and memory are limited
- Inference must be real-time during mobility
Dataset realism - Mobility/blockage datasets are difficult to collect
- Simulated data may not match real propagation
- Training-deployment mismatch reduces reliability
Beam misalignment risks - Incorrect prediction may select wrong beam
- Can trigger beam failures and throughput loss
- Requires fallback and confidence mechanisms
Specification and interworking issues - AI procedures must coexist with NR beam management
- Need LCM, capability signaling, and fallback behavior
- Must ensure predictable performance for operators
Overall complexity - AI enables predictive and efficient beam management
- But introduces new design and validation challenges
Channel Coding Enhancement
In 6G, channel coding has to support much larger data blocks and much higher peak throughput than NR, while keeping BLER in the same tight range and staying within realistic UE complexity. NR already pushed LDPC and polar codes close to their practical limits, but the basic assumptions were still "moderate" TBS, moderate numbers of layers and ports, and relatively static base graphs. When we move to 6G with very wide bandwidths, FR3 operation, massive MIMO and extremely high data rates, the existing LDPC base graphs and lifting factors start to look rigid. They require heavy puncturing/shortening to fit large TBS, they can show error-floor issues in some regimes, and the decoder complexity can explode if we just increase iterations or add ad-hoc scaling. The RAN1 122bis AI/ML documents already recognize this pressure and explicitly list AI/ML-based channel coding as a 6G use case, with LDPC decoding optimization as the first concrete example. In parallel, RAN1 also shows how AI-predicted bit-level priors can significantly boost convolutional and polar decoders for DCI, giving large BLER gains in some scenarios. This suggests a broader direction: instead of designing entirely new code families from scratch, 6G can keep QC-LDPC as a baseline, but use AI/ML both to optimize long-block LDPC behavior (e.g., edge weights, node scheduling, puncturing patterns) and to guide the introduction of new base graphs and lifting values tailored to large TBS.
Overall, "Channel Coding Enhancement" for large data in 6G is less about replacing LDPC and more about letting AI/ML optimize how LDPC is used and how new LDPC structures are designed. In a conservative path, AI primarily assists decoding and offline base-graph design, and the final standard still specifies fixed QC-LDPC matrices and lifting values. More radical directions such as fully learned codes or JSCC-style coding for large PDSCH blocks may remain as research topics or highly specialized options for particular links.
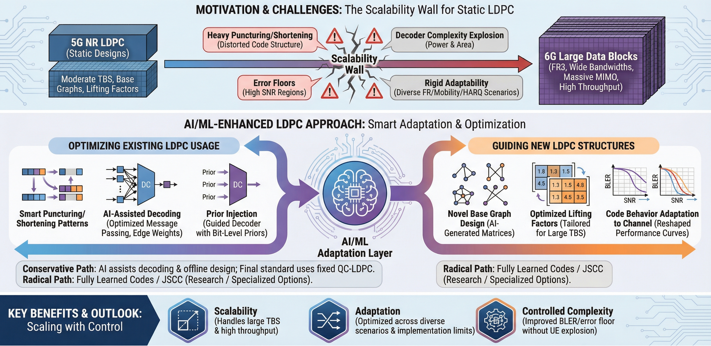
Motivation
The main motivation for AI/ML in channel coding for large data is that static LDPC designs do not scale gracefully when both codeword length and required throughput grow. In NR, the current base graphs and lifting values were tuned for a certain range of TBS, code rates, and layer numbers. They already work close to the limit in many scenarios. When 6G pushes to much larger TBS and higher peak rates, we usually extend the same design by heavier puncturing, shortening, or concatenation. This keeps the implementation simple, but the code structure becomes distorted. Minimum distance gets worse, harmful short cycles appear more often, and the error floor starts to show up exactly in the high-SNR region where 6G wants to operate. At the same time, decoders must run faster and support more parallelism. A straightforward way is to increase the number of iterations or add more ad-hoc tweaks like scaling and damping, but this quickly explodes power and area on the UE side. The problem gets even harder when we consider that 6G will not use a single “typical” channel. It must cover FR1, upper-mid bands, and FR3, different mobility levels, different HARQ strategies, and different segmentation patterns. A single frozen LDPC design with fixed base graphs and lifting values cannot be optimal across all these axes. So we need a way to adapt code behavior to channel conditions, to large-block structures, and to implementation limits. AI/ML gives this missing adaptation layer. It can reshape how messages are passed in the decoder, how priors are injected, and how base graphs and liftings are chosen during design. Therefore the core motivation is simple: if we keep static LDPC, we hit a scalability wall in BLER, error floor, and complexity for large data. If we combine LDPC with AI/ML, we get a realistic chance to keep error performance and complexity under control even as 6G pushes codeword length and throughput far beyond NR.
Scaling limitations of existing LDPC designs - Large transport blocks in 6G push NR LDPC base graphs into regimes requiring heavy puncturing, shortening, or concatenation.
- These operations often harm minimum distance and increase the error floor.
- Decoder complexity grows quickly if we simply increase the number of iterations or add ad-hoc scaling.
Mismatch with heterogeneous 6G channels - 6G must operate across FR1, upper-mid bands, and FR3 with very different fading and interference characteristics.
- The same static base graphs and lifting factors may not be optimal across all these scenarios.
- Different HARQ and segmentation strategies further diversify the effective code configurations.
Need for data-aware and channel-aware coding - Large data streams and structured payloads (e.g., CSI, control) have statistics that fixed LDPC designs do not exploit.
- AI/ML enables adapting the use of LDPC to instantaneous channel and code configuration.
- It also enables offline optimization of new base graphs and lifting values tuned for large TBS.
Methodology
Channel coding enhancement for large data in 6G can be viewed as having two main layers, each addressing a different limitation of the current NR LDPC design. The first layer focuses on improving how we use the existing LDPC structure during decoding, without modifying the underlying parity-check matrix. This is essential because QC-LDPC is extremely hardware-friendly, and any modification to the matrix structure immediately affects memory layout, routing, and parallelization in the decoder. AI/ML provides a way to inject intelligence into the decoding process while preserving full compatibility with existing hardware blocks. The second layer focuses on the offline design of new LDPC base graphs and lifting values specifically optimized for very large transport blocks expected in 6G. This part is more fundamental: instead of stretching NR LDPC beyond its comfort zone using puncturing or shortening, AI/ML can automatically explore the enormous combinatorial space of graph structures, degree distributions, and circulant shifts to find designs that maintain minimum distance, reduce harmful cycles, and stay hardware-friendly at scale. Together, these two layers allow 6G to evolve LDPC in a way that is both backward-compatible and capable of supporting much larger data blocks and much higher throughput than NR.
Layer 1: AI-assisted decoding on existing or extended LDPC structures - Keep QC-LDPC as the hardware-friendly baseline.
- Use AI/ML to improve belief-propagation behavior without changing the underlying parity-check matrix.
- Examples include:
- Neural LDPC decoding: a model takes channel LLRs, Tanner graph structure, and iteration index and outputs optimized scaling weights or per-edge updates.
- Prior-aided decoding: a neural network (e.g., Bi-LSTM + dense layers) predicts bit-level priors or reliability weights that feed into a classical LDPC decoder.
- Iteration control: AI models decide when to stop iterations or how to adjust damping to avoid divergence and reduce latency.
- For large blocks, this layer helps:
- Reduce the number of iterations required for convergence.
- Mitigate error floors caused by harmful cycles or trapping sets.
- Maintain BLER performance under a wide range of SNRs and channel conditions.
Layer 2: AI-assisted design of new base graphs and lifting values - Start from QC-LDPC templates and treat base-graph and lifting choices as optimization variables.
- Use AI/ML (e.g., reinforcement learning or gradient-guided search) to explore:
- Variable and check node degree distributions.
- Edge placements in the base graph to control cycles and trapping sets.
- Lifting factors and circulant shifts that match target TBS and OFDM resource structures.
- Evaluate candidate designs with BLER, throughput, and complexity metrics.
- Use full simulation for a subset of candidates.
- Optionally use AI-based surrogate models to approximate performance for faster search.
- Target outcomes:
- Base graphs that keep good minimum distance and low error floors for large blocks.
- Designs tailored to specific 6G scenarios (e.g., wideband FR3 PDSCH, high-rank MIMO).
- QC structures that remain implementable in practical decoders.
Models
In the large-data regime of 6G, AI-assisted channel coding requires model architectures that can capture the complex statistical structure of extremely long LDPC codewords and the dynamic behavior of belief-propagation decoding under diverse channel conditions. Traditional LDPC decoding relies on local message passing with fixed update rules, but this becomes insufficient when transport block sizes grow, when the channel varies across frequency and time, or when puncturing and shortening create irregular reliability patterns inside the codeword. As a result, the models used in 6G channel-coding enhancement must extract information not only from individual LLRs but also from the broader relationships among bits, parity-checks, and graph topology. Recurrent models such as Bi-LSTM can analyze long sequences of soft information and predict bit-level reliability before decoding begins. Fully connected networks can learn per-iteration or per-edge scaling factors that refine BP message updates without changing the LDPC structure. Graph neural networks (GNNs) can operate directly on the Tanner graph, learning how messages should flow across thousands of nodes, which becomes essential as block sizes increase. Transformer models provide a way to capture long-range dependencies that classical BP cannot handle, while autoencoder-based designs open the door to hybrid coding structures that blend LDPC with learned components. Lightweight CNN or MLP variants act as practical, low-power modules for UE-side implementations, offering small but consistent gains with minimal overhead. Together, these model families form an adaptable toolbox that lets 6G maintain strong error-correction performance even as codeword sizes, throughput targets, and channel variability reach levels far beyond what NR LDPC was originally designed to support.
Bi-LSTM + dense layers for prior-aided decoding - Operate on sequences of LLRs, parity-check outcomes, or higher-level features.
- Predict bit-level priors or reliability weights for the LDPC decoder.
- Can be applied to long LDPC codewords by segmenting or grouping bits.
Fully connected networks for LDPC weight optimization - Take as input iteration index, SNR, or local graph features.
- Output scaling factors or message-update weights for edges or node groups.
- Implement "neural BP" behavior while preserving the underlying LDPC structure.
Graph neural networks (GNNs) - Represent the LDPC Tanner graph explicitly as a bipartite graph.
- Use message-passing layers parallel to BP iterations.
- Learn to weight and schedule messages for faster convergence and lower BLER.
Transformer and autoencoder models for JSCC-like designs - Treat the encoder and decoder as an autoencoder around a fixed channel layer.
- Use attention to capture long-range dependencies in large blocks.
- More suited for special links (e.g., CSI feedback) than general PDSCH, but conceptually related.
Challenges
Deploying AI/ML-based channel-coding enhancement for large data in 6G introduces several practical challenges because the decoding process must remain extremely reliable and tightly timed, even as neural components add complexity. Long LDPC codewords already stretch decoder memory, bandwidth, and iteration budgets, and inserting AI-based modules risks exceeding HARQ deadlines or UE power limits. Another difficulty is generalization: models trained on specific SNR ranges, lifting factors, or channel profiles may behave unpredictably when exposed to FR3 mobility, hardware impairments, or interference conditions not seen during training. Producing training data that covers all relevant configurations is expensive, and mismatch between simulated and real-world channels can cause unexpected BLER behavior. Integrating AI models into hardware-friendly QC-LDPC pipelines is also challenging because the decoder demands deterministic behavior, fixed latency, and strict quantization rules. Standardization adds further constraints, since AI-assisted decoding must be reproducible across vendors and cannot depend on model retraining. Finally, operators require explainable and stable behavior—any sudden BLER spikes or non-deterministic decoding outcomes would not be acceptable in commercial networks. These factors make AI-enhanced coding promising, but they also require careful engineering to ensure robustness and practicality.
Complexity and latency for long blocks - Large TBS implies long LDPC blocks and many parity checks.
- Any neural component must fit within tight decoding time budgets.
- HARQ timing and UE power constraints limit model size and depth.
Training data and channel diversity - Training must cover FR1, upper-mid, and FR3 channels, different MIMO orders, and interference conditions.
- Generating such datasets is computationally expensive.
- Insufficient diversity can lead to performance degradation in the field.
Generalization across code configurations - 6G will use multiple code rates, block sizes, and segmentation patterns.
- Models trained for one configuration may not generalize to others.
- Either many per-configuration models are needed, or architectures must be structure-aware (e.g., GNN-based).
Compatibility with QC-LDPC hardware and standardization - Parity-check matrices must remain quasi-cyclic and hardware-friendly.
- Standardization requires deterministic, frozen code descriptions rather than "train your own" codes.
- AI may be used offline to propose new base graphs, which are then standardized as fixed structures.
Reliability and explainability - Operators are sensitive to rare BLER spikes and error floors.
- AI-driven decoders must show robust, predictable performance across corner cases.
- Opaque model behavior complicates debugging, certification, and acceptance.
JSCC / JSCCM Enhancement
In 6G, Joint Source–Channel Coding (JSCC) and Joint Source–Channel Coding & Modulation (JSCCM) are explored as key AI-native techniques to rethink how information is represented over the physical layer. Instead of treating source coding, channel coding, and modulation as strictly separated blocks, JSCC/JSCCM learns an end-to-end mapping from the input information to the transmitted waveform and back, with the channel represented as a fixed layer in between. This paradigm is particularly attractive in 6G for highly structured payloads such as CSI feedback, control information, and short packets, where classical separate designs are inefficient or difficult to optimize. It also fits naturally with two-sided AI/ML use cases discussed in the RAN1 documents, where both transmitter and receiver can be redesigned jointly under a common learning framework. As a result, JSCC/JSCCM becomes a central use case for AI-enhanced PHY, enabling better robustness and compression of critical information under realistic 6G channel conditions.
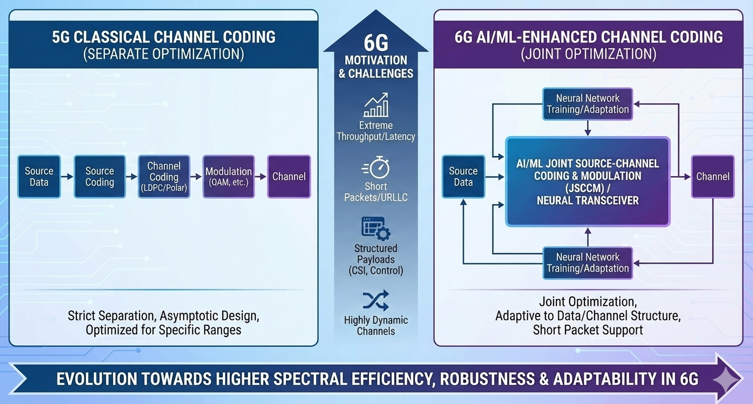
Motivation
The motivation for JSCC/JSCCM in 6G comes from the limitations of the conventional “separation principle” when applied to short-blocklength, structured, or highly constrained feedback scenarios. Traditional designs first apply source compression, then channel coding, then modulation, assuming ideal interfaces between these layers and asymptotically long blocks. In 6G, many key payloads such as CSI, beam-related feedback, or DCI are short, highly structured, and extremely sensitive to delay and error. Under these conditions, separate design leads to suboptimal use of bits and radio resources, and the overhead of protecting and quantizing such information can become a bottleneck. JSCC/JSCCM addresses this by allowing the system to learn redundancy and symbol mapping jointly, directly over the physical channel model, and by tailoring the representation to the actual statistics of the payload and the channel. This provides a path to reduce overhead for CSI/feedback, improve robustness in harsh channels, and enable new types of PHY-level representations, including for ISAC or other 6G-advanced scenarios.
Classical separation-based design assumes: - Independent source coding, channel coding, and modulation blocks
- Asymptotically long blocklengths and ideal interfaces
- Relatively simple and stationary channel models
In 6G, these assumptions break down because: - Key payloads (CSI, DCI, control) are short and highly structured
- Strict latency and reliability constraints limit blocklengths
- Channels can be highly frequency-selective, mobile, and non-stationary
Separate designs under these conditions lead to: - Redundant overhead for critical feedback and control
- Performance loss in low-SNR and short-blocklength regimes
- Difficulty exploiting true payload statistics in encoding
JSCC/JSCCM becomes attractive because it can: - Learn end-to-end mappings over realistic channel models
- Jointly optimize redundancy, symbol mapping, and reconstruction
- Exploit structure in CSI, control, or sensing-related payloads
Consequently: - 6G can compress and protect critical information more efficiently
- Two-sided AI PHY designs become feasible for selected use cases
Methodology
The JSCC/JSCCM methodologies considered for 6G in the RAN1 discussions typically model the physical layer as an autoencoder, where the encoder corresponds to the transmitter-side mapping and the decoder to the receiver-side reconstruction, with the channel inserted as a non-trainable layer. For JSCC, the encoder operates on digital payload representations (e.g., CSI matrices or control bits) and outputs a sequence of channel symbols, while the decoder reconstructs the payload from noisy received symbols. For JSCCM, the mapping is extended down to the modulation level, allowing the constellation and symbol statistics themselves to be learned rather than fixed. Variants exist where JSCC/JSCCM is used only for specific sub-blocks (e.g., CSI feedback fields) while other parts of the system remain conventional. The training process can include multiple channel conditions, SNRs, and interference profiles so that the learned mapping is robust across a range of deployment scenarios. Some proposals also integrate JSCC/JSCCM with higher-layer coding (e.g., FEC used as an outer code) to combine the benefits of learned inner mappings with the robustness of standardized outer codes.
End-to-end autoencoder formulation - Model PHY as encoder–channel–decoder chain
- Train encoder and decoder jointly over a fixed channel model
- Target minimal reconstruction error or task-specific loss
JSCC for digital payloads (e.g., CSI, control) - Encode structured payloads directly into channel symbols
- Learn redundancy tailored to payload and channel statistics
- Reduce feedback or control overhead versus separated designs
JSCCM with learned modulation - Extend learning down to the modulation/constellation level
- Allow non-standard symbol distributions optimized for robustness
- Jointly design symbol mapping and reconstruction
Hybrid schemes with outer codes - Use JSCC/JSCCM as an inner mapping under standard FEC
- Combine learning flexibility with known code performance
- Facilitate smoother integration into standardized systems
Overall goal - Improve robustness and compression of key PHY payloads
- Enable AI-native, two-sided optimizations where beneficial
Models
JSCC/JSCCM use cases rely primarily on autoencoder-style neural architectures. Encoder and decoder blocks can be implemented using fully connected networks, CNNs, or Transformer-like modules, depending on the structure of the payload (e.g., matrix-shaped CSI or vectorized control fields). For CSI-oriented JSCC, CNNs and attention-based models are useful to capture spatial and frequency correlations, while Transformers are effective when the payload can be viewed as a sequence. Variational autoencoders (VAEs) or other latent-variable models may be used to enforce compact, well-structured latent spaces for better compression and robustness. In some proposals, JSCC is combined with JSCCM through multi-branch or multi-head architectures, where different latent dimensions map to different parts of the signal or spectrum. Lightweight decoders and quantization-aware training are considered when JSCC decoding must run on UE hardware under tight complexity constraints.
Standard autoencoders - Serve as the basic JSCC/JSCCM encoder–decoder framework
- Use MLP, CNN, or Transformer blocks depending on payload type
- Train end-to-end over the channel layer
CNN- and attention-based encoders/decoders - Capture spatial/frequency structure of CSI or similar payloads
- Improve robustness to noise and interference
Transformer-based JSCC/JSCCM - Model payloads as sequences of tokens or blocks
- Use self-attention to handle long-range dependencies
Variational and latent-variable models - Create compact, well-regularized latent representations
- Support better compression and robustness to channel variation
Lightweight and quantization-aware decoders - Adapt JSCC/JSCCM decoding to UE-side resource constraints
- Allow deployment under limited precision and memory
Overall toolbox - Covers a range from simple MLP autoencoders to advanced attention-based models
- Allows tuning complexity versus performance for different 6G scenarios
Challenges
Despite its promise, JSCC/JSCCM also introduces several challenges for 6G deployment. Reliability and predictability are major concerns, because JSCC/JSCCM changes the basic relationship between bits and waveforms, making it harder to analyze performance using classical coding theory. Interoperability is another key issue: both ends of the link must share the same learned mapping, so LCM procedures, versioning, and fallback behavior must be clearly defined. Complexity and latency can be higher than in conventional separated designs, especially if the encoder and decoder are large. Training robustness is also critical; models must perform well over a wide range of SNRs and channel conditions, including those not perfectly represented in the training set. Finally, aligning JSCC/JSCCM with standardization processes requires careful identification of which use cases justify two-sided learning and how these schemes coexist with legacy, bit-level interfaces and code structures.
Reliability and analytical guarantees - End-to-end learned mappings lack classical coding bounds
- Harder to certify worst-case performance and error floors
Interoperability and LCM - Both ends must share and manage the same JSCC/JSCCM model
- Requires robust lifecycle management and version control
Complexity and latency - Encoder/decoder networks may be heavier than classical blocks
- UE-side decoding must meet strict timing and power budgets
Training coverage and robustness - Training must cover diverse channels, SNRs, and interference patterns
- Distribution shifts can degrade performance in the field
Standardization and coexistence - Need to define where JSCC/JSCCM is allowed and how it coexists with legacy PHY
- Must ensure compatibility with bit-oriented interfaces and higher-layer protocols
Overall complexity - JSCC/JSCCM offers powerful two-sided AI capabilities
- But adds significant challenges in analysis, deployment, and standardization
Energy Efficiency Enhancement
In 6G, energy efficiency becomes a primary design objective rather than a secondary optimization, because networks must support massive traffic growth, dense deployments, and new service types while keeping operational and environmental costs under control. Traditional mechanisms for reducing power consumption, such as static cell switch-off, fixed DRX configurations, and simple load-based sleep modes, are no longer sufficient when traffic is highly dynamic across time, frequency, and space. 6G must coordinate energy-saving actions across multiple layers, including RF, baseband, scheduling, and protocol procedures, without causing unacceptable degradation in coverage, latency, or user experience. AI/ML provides a way to learn traffic patterns, load evolution, and channel characteristics, enabling more precise and proactive control of when and where resources are activated or put into low-power states. As a result, AI-enhanced energy efficiency is positioned as a key use case in 6G, closely tied to features such as Network Energy Saving (NES) and UE Power Saving (UEPS).
Motivation
The motivation for applying AI/ML to energy efficiency in 6G arises from the growing gap between static energy-saving schemes and the complex, time-varying behavior of real networks. Existing techniques often rely on threshold-based rules that are not aware of future traffic, mobility patterns, or service requirements. This can lead either to missed energy-saving opportunities or to aggressive power-saving actions that harm coverage, throughput, and latency. In dense 6G deployments with many cells, beams, carriers, and frequency bands, the number of possible energy-saving configurations becomes very large, and exploring them manually or with simple heuristics is impractical. AI/ML can learn to predict traffic load, user distribution, and QoS demands, and can map these predictions to energy-control actions such as cell and carrier activation, symbol muting, and DRX parameter selection. This enables finer-granularity and more context-aware energy-saving behavior than traditional methods can provide.
Conventional energy-saving mechanisms rely on: - Static or semi-static cell switch-off policies
- Predefined DRX configurations and timers
- Simple load thresholds for sleep and wake decisions
These mechanisms are insufficient in 6G because: - Traffic is highly dynamic in time, frequency, and location
- Dense deployments create a huge configuration space
- Threshold rules do not anticipate future load or QoS needs
As a result, traditional schemes may cause: - Missed energy-saving opportunities during low-load periods
- Over-aggressive sleeping that harms coverage and latency
- Inconsistent user experience across cells and time
AI/ML becomes necessary because it can: - Predict traffic load and user distribution in advance
- Learn context-aware policies for NES and UEPS
- Jointly consider energy, throughput, and QoS constraints
Consequently: - 6G can realize deeper power savings without degrading service
- Energy control can be applied at finer granularity (cells, beams, symbols, UEs)
- Networks move from reactive thresholds to proactive energy management
Methodology
The methodologies for AI-based energy efficiency in 6G can be divided into several categories. The first is traffic- and load-prediction driven control, where models forecast future cell or beam load and then activate or deactivate resources accordingly, including carrier on/off, symbol muting, and sleep modes for RF chains and baseband units. The second is AI-based NES policy optimization, where the network learns policies for switching cells, sectors, or beams into low-power states while preserving coverage and handover performance. A third methodology is UE power-saving enhancement, in which DRX and other UE-side configurations are tuned based on predicted traffic patterns and application behavior to minimize wake-ups and unnecessary measurements. Another direction is joint energy- and performance-aware scheduling, where schedulers are trained to choose resource allocations that balance throughput, latency, and power, for example by concentrating activity in shorter time windows to increase sleep opportunities. Finally, cross-layer energy coordination leverages AI/ML to align PHY/MAC actions with higher-layer policies such as slicing or service prioritization.
Traffic and load prediction for energy control - Predict future cell and beam load using historical data
- Drive carrier and cell on/off decisions
- Enable proactive, rather than reactive, power-saving actions
AI-based NES (Network Energy Saving) policy optimization - Learn when and where to switch cells, sectors, or beams to low-power states
- Maintain coverage and mobility robustness
- Exploit spatial diversity of traffic to save power
UE power-saving enhancement (UEPS) - Adjust DRX and measurement patterns using traffic predictions
- Reduce unnecessary wake-ups and control signaling
- Coordinate UE sleep behavior with network scheduling
Energy-aware scheduling and resource allocation - Train schedulers to consider both throughput and energy metrics
- Cluster transmissions to create longer sleep opportunities
- Adapt MCS, bandwidth, and time-domain allocation for power saving
Cross-layer energy coordination - Align PHY/MAC energy actions with higher-layer policies
- Use AI/ML to map service-level requirements to low-level power states
- Support slice-specific or service-specific energy profiles
Overall goal - Reduce network and UE power consumption significantly
- Preserve or improve user-perceived QoS
Models
For energy efficiency use cases, several AI/ML model types are especially relevant. Time-series models such as LSTM, GRU, and temporal convolutional networks are used for traffic and load prediction across cells, carriers, or beams. Reinforcement learning (RL) and deep RL algorithms are employed to learn NES and UEPS policies that balance energy savings against QoS degradation, often using reward functions that combine power, throughput, and latency. Graph neural networks can represent the spatial relationships between cells and beams in dense networks, enabling coordinated energy decisions across multiple nodes. Lightweight MLP or decision-tree-based models may be used for on-device DRX configuration or simple policy decisions where complexity must be minimized. In some cases, hybrid approaches combine prediction models with RL-based policy layers to separate forecasting from decision-making.
Time-series prediction models (LSTM / GRU / TCN) - Forecast traffic load and user activity over time
- Provide inputs for proactive NES and UEPS decisions
Reinforcement learning and deep RL - Learn energy-control policies via trial-and-error or simulation
- Optimize long-term trade-offs between power and QoS
Graph neural networks - Model spatial relationships in dense, multi-cell deployments
- Enable coordinated energy-saving actions across neighboring cells
Lightweight MLP and tree-based models - Support low-complexity decision-making on UEs or edge nodes
- Implement simple, explainable energy policies
Hybrid prediction–policy architectures - Combine load prediction models with RL-based action selection
- Separate forecasting from control to improve stability
Overall toolbox - Covers prediction, policy learning, and spatial coordination
- Allows tuning of complexity and responsiveness per deployment
Challenges
AI/ML-based energy efficiency in 6G faces several important challenges. First, incorrect or overly aggressive energy-saving actions can create coverage holes, increase call drops, or violate latency and reliability targets, so policies must be conservative and well-validated. Second, training data for energy use cases must capture a wide range of traffic patterns, including rare peaks and special events, otherwise models may fail under unusual load. Third, the interaction between energy-control policies and other RAN functions such as mobility, scheduling, and interference management is complex, making it difficult to predict the full system impact of a given policy. Fourth, implementing RL or complex models for NES at scale raises questions about stability, convergence, and explainability, which operators require before trusting automated control. Finally, standardization must define how AI-controlled energy features expose their capabilities, report their states, and fall back to safe default behavior when models are unavailable or uncertain.
Risk of QoS degradation - Over-aggressive energy saving can harm coverage and latency
- Policies must avoid creating service outages or instability
Training data completeness - Traffic datasets must include peaks, anomalies, and special events
- Insufficient coverage can cause policies to fail in rare but critical cases
Complex interactions with other RAN functions - Energy-saving actions affect mobility, interference, and scheduling
- End-to-end impact is difficult to analyze and predict
Stability and explainability of control policies - RL-based or complex policies may be hard to interpret
- Operators require predictable and explainable behavior
Standardization and fallback behavior - Need clear frameworks for capability signaling and state reporting
- Must define safe fallback modes when AI models are unavailable or uncertain
Overall complexity - AI/ML offers powerful tools for energy efficiency
- But increases the complexity of design, validation, and operation
Initial Access Enhancement
In 6G, initial access must cope with much narrower beams, larger antenna arrays, and operation over wider frequency ranges, including FR3, than in 5G. The legacy NR approach relies heavily on SSB-based cell search and PRACH-based random access, with beam sweeping on the downlink and potentially on the uplink. As the number of beams, cells, and carriers increases, exhaustive or semi-exhaustive sweeping becomes too slow and too costly in terms of overhead and UE power. In addition, blockage, mobility, and multi-TRP deployments make the initial access process more fragile, since the best beam or TRP may change quickly or be temporarily unavailable. AI/ML enables 6G to move from brute-force sweeping to predictive and inference-based initial access, where the network and UE use prior information and learned models to narrow down beam and cell candidates, detect PRACH more robustly, and reduce access delay. As a result, initial access enhancement with AI/ML becomes a key use case for improving both user experience and network efficiency in 6G.
Motivation
The motivation for applying AI/ML to initial access arises from the scaling limitations of classical NR procedures when extended to 6G. SSB and CSI-RS sweeping over many narrow beams induces large broadcast overhead and long discovery times, especially when multiple carriers or TRPs must be searched. PRACH detection and preamble multiplicity estimation also become more challenging in dense deployments, where collisions and interference increase. At the same time, 6G aims for faster access, better coverage in challenging environments, and support for a wide variety of device types, including low-power and high-mobility UEs. Static initial access configurations and simple threshold-based detection are not enough to meet these requirements. AI/ML can incorporate context such as location, historical measurements, and environment statistics to prioritize beams and cells, predict which TRPs are likely to serve a UE, and improve PRACH detection under interference and multi-path. This allows initial access to become more targeted, faster, and more robust.
Conventional initial access relies on: - SSB-based cell search with beam sweeping
- CSI-RS-based beam refinement after detection
- PRACH preambles with threshold-based detection at the gNB
In 6G, this approach faces issues because: - Beam counts and TRP numbers increase significantly
- Exhaustive sweeping causes high overhead and long access delay
- Blockage and mobility make the best beam/TRP time-varying
As a result, classical IA(Initial Access) can lead to: - Slow cell/beam discovery
- Higher access failure rates in dense or high-frequency deployments
- Increased UE energy consumption during search
AI/ML becomes attractive because it can: - Predict promising beams, cells, or TRPs before sweeping
- Improve PRACH detection and multiplicity estimation under interference
- Use context and historical data to guide IA decisions
Consequently: - 6G can reduce IA overhead and latency
- Initial access becomes more robust and energy-efficient
Methodology
AI-based initial access enhancement in 6G can be organized into several major methodologies. The first is beam and cell prediction for IA, where models use historical CSI, location, and mobility patterns to predict the most likely serving beams or cells for a UE, thereby narrowing the search space before SSB or CSI-RS sweeping. The second is AI-based PRACH reception and multiplicity detection, using neural receivers to detect weak preambles and distinguish multiple UEs transmitting the same preamble under interference and noise. A third methodology is context-aware IA configuration, where AI/ML maps UE or environment features (e.g., time-of-day, traffic patterns, mobility class) to IA parameters such as SSB periodicity, beam sweeping order, and PRACH resources. Another direction is cross-frequency IA assistance, where information from legacy bands or previous connections is used to inform beam or cell selection at higher frequencies, including FR3. Together, these approaches aim to accelerate IA, reduce mis-detections and false alarms, and lower the UE and network energy cost of entering the system.
Beam and cell prediction for IA - Predict likely serving beams or cells using historical measurements
- Reduce the number of beams and cells that must be searched
- Shorten IA latency and lower sweeping overhead
AI-based PRACH reception and multiplicity detection - Use neural receivers for robust preamble detection
- Estimate the number of UEs using the same preamble
- Improve RA reliability in dense or high-interference scenarios
Context-aware IA configuration - Adapt SSB periodicity and beam sweeping patterns to conditions
- Allocate PRACH resources based on predicted demand
- Tailor IA procedures to UE type and service requirements
Cross-frequency and history-based IA assistance - Leverage information from lower bands or past sessions
- Guide IA at higher-frequency bands (including FR3)
- Improve robustness under blockage and mobility
Overall goal - Make initial access faster, more reliable, and more energy-efficient
- Scale IA procedures to dense, multi-band, multi-TRP 6G deployments
Models
The models used for initial access enhancement in 6G reflect the sequential and spatial nature of the problem. Sequence models such as LSTM, GRU, and Transformers are useful for beam and cell prediction, since they can learn patterns in historical CSI, beam indices, or mobility traces. CNN-based models are well-suited for PRACH reception, where the time–frequency structure of the received signal can be treated as an image-like grid for detection and multiplicity estimation. Lightweight MLP models can be employed for context-to-configuration mapping, translating simple features into IA parameter settings. In some proposals, hybrid models combine location-based features (e.g., coarse positioning information) with CSI features to improve prediction accuracy. The choice of model depends on where the inference runs (gNB or UE) and on the available compute resources and latency constraints.
Sequence models (LSTM / GRU / Transformers) - Learn temporal patterns in CSI, beam, or cell histories
- Predict candidate beams or cells for IA
- Support mobility-aware IA strategies
CNN-based PRACH receivers - Treat PRACH time–frequency samples as 2D inputs
- Perform robust preamble detection and multiplicity estimation
- Handle interference and multi-path more effectively than simple detectors
Lightweight MLP models for configuration - Map context features to IA parameters (SSB periodicity, beam order, PRACH config)
- Allow low-complexity deployment at gNB or RIC
Hybrid feature models - Combine location, CSI, and historical KPIs
- Improve accuracy of beam/cell prediction and IA configuration
Overall toolbox - Covers prediction, detection, and configuration tasks
- Allows adapting model complexity to deployment needs
Challenges
AI/ML-based initial access also faces several challenges that must be addressed for 6G deployment. One key issue is generalization: models trained for IA in a given environment or deployment may not perform well when cell layouts, blockage patterns, or UE distributions change. Another challenge is timing—IA procedures operate under tight latency constraints, so beam prediction and PRACH detection must run quickly enough not to delay access. Data collection for training can be difficult, especially for rare IA failure modes or edge cases such as sudden blockage or extreme mobility. Mis-prediction of beams or cells can lead to longer access times, repeated RA attempts, or even access failures, so robust fallback strategies to classical NR IA are needed. Finally, integrating AI-based IA with existing RRC, NAS, and higher-layer procedures requires careful definition of capability signaling, measurement reporting, and model lifecycle management.
Generalization and environment changes - Models may not transfer well across deployments or scenarios
- Requires mechanisms for adaptation or retraining
Latency and complexity constraints - IA procedures must complete within strict timing budgets
- Inference must be lightweight enough for practical gNB/UE hardware
Training data and edge cases - Need data covering rare IA failures and extreme conditions
- Simulation-based data may not reflect all real-world impairments
Risk of mis-prediction - Wrong beam or cell predictions can prolong access time
- Must define fallbacks to classical sweeping and PRACH handling
Specification and integration - AI-based IA must coexist with existing RRC/NAS procedures
- Need clear capability signaling, measurement definitions, and LCM for IA models
Overall complexity - AI enables faster, smarter initial access
- But introduces new complexity in design, validation, and operation
Mobility Enhancement
In 6G, mobility procedures must operate under much more complex conditions than in 5G: denser deployments, multi-TRP and multi-panel topologies, operation in upper-mid bands and FR3, and tighter requirements on both reliability and latency. Classical handover, measurement, and cell/beam selection mechanisms were designed around relatively simple thresholds and event triggers, assuming moderate cell densities and limited beam counts. As networks evolve toward extremely dense, multi-layer architectures with narrow beams and dynamic traffic patterns, these mechanisms can lead to excessive measurement overhead, ping-pong events, and handover failures. AI/ML enables 6G to move from purely threshold-based mobility to prediction- and context-based mobility, where the network and UE leverage learned models to anticipate mobility events, optimize measurement configurations, and select cells and beams more intelligently. As a result, mobility enhancement with AI/ML is considered a key use case, especially in the context of high-frequency and high-speed scenarios.
Motivation
The motivation for applying AI/ML to mobility comes from the limitations of conventional handover and reselection procedures when extended to dense, beam-centric 6G deployments. Legacy mechanisms rely on RSRP/RSRQ/SINR thresholds and hysteresis-based events (e.g., A3, A5) with static or semi-static measurement configurations. In dense deployments, this can result in frequent event triggering, large measurement reporting overhead, and suboptimal target-cell selection, particularly for UEs in high mobility or at cell edges. In upper-frequency bands, the environment changes rapidly due to blockage and fast fading, making it difficult to maintain stable coverage using simple rules. AI/ML can exploit historical mobility traces, radio measurements, and context (location, time-of-day, traffic) to predict future serving cells or beams, adjust measurement and reporting behavior, and anticipate handover needs. This allows 6G to reduce unnecessary measurements and signaling while improving handover robustness and user experience.
Classical mobility mechanisms assume: - Threshold- and hysteresis-based events for HO and reselection
- Static measurement configurations and reporting periodicities
- Moderate cell density and limited beam granularity
These assumptions fail in 6G because: - Cell and TRP densities are much higher
- Beams are narrow and numerous, especially in FR3
- Blockage and high mobility cause rapid channel variation
As a result, traditional mobility can lead to: - Excessive measurement and reporting overhead
- Ping-pong handovers and HO failures
- Suboptimal cell/beam choices for moving UEs
AI/ML becomes attractive because it can: - Predict future serving cells, beams, or TRPs using historical data
- Optimize measurement and reporting behavior contextually
- Balance mobility robustness with signaling and power cost
Consequently: - 6G can provide more stable mobility with reduced overhead
- Mobility procedures become more predictive and less reactive
Methodology
AI-based mobility enhancement methods in 6G can be grouped into several categories. The first is handover prediction and target-cell/beam recommendation, where models use UE measurement histories, location estimates, and network context to predict when a handover is needed and which candidate cells or beams are most suitable. The second is adaptive measurement configuration, where AI/ML selects or tunes measurement objects, report types, filtering, and periodicities based on UE mobility state, service type, and environment, thereby reducing unnecessary measurements while maintaining HO reliability. A third methodology is AI-assisted cell and beam reselection, especially for idle mode, where the network or UE learns preferred cells for different locations and times to optimize camping and reselection behavior. Another direction is mobility robustness optimization, where models analyze HO outcomes (e.g., failures, ping-pongs, radio link failures) and automatically adjust parameters or policies to reduce such events. Finally, AI can be used for multi-TRP and multi-layer mobility coordination, selecting appropriate TRP/beam combinations for serving and secondary links in advanced dual-connectivity or multi-TRP scenarios.
Handover prediction and target recommendation - Predict when a HO will be needed based on historical measurements
- Rank candidate target cells or beams
- Reduce late or unnecessary handovers
Adaptive measurement configuration - Adjust measurement objects and report criteria based on UE context
- Reduce measurement overhead for low-mobility or stable UEs
- Increase responsiveness for high-mobility or edge UEs
AI-assisted selection and reselection - Learn preferred cells and beams for idle and connected modes
- Use location/time-based patterns to guide reselection
- Improve camping decisions and reduce access delay
Mobility robustness optimization - Analyze HO failures, RLFs, and ping-pongs
- Automatically tune mobility parameters and thresholds
- Improve HO success rate and connection stability
Multi-TRP and multi-layer mobility coordination - Select appropriate TRP/beam sets for dual connectivity or multi-TRP
- Coordinate primary and secondary links during mobility
- Enhance robustness in dense and high-frequency deployments
Overall goal - Provide robust, low-overhead mobility in dense 6G networks
- Leverage prediction and context instead of only thresholds
Models
Mobility-related AI/ML models must handle temporal, spatial, and contextual information. Sequence models such as LSTM, GRU, and Transformers are natural fits for handover prediction and mobility state classification, since they can learn patterns in measurement reports, beam indices, and HO histories. Time-series forecasting models can predict future signal levels or cell quality to support proactive HO decisions. For location- and topology-aware mobility, graph neural networks can model cell adjacency, TRP relationships, and UE–cell associations. Lightweight MLPs or tree-based models are suitable for parameter selection and mobility robustness optimization where interpretability and low complexity are important. In some proposals, hybrid models combine location, CSI, and higher-layer KPIs as features to provide more accurate and robust mobility decisions.
Sequence models (LSTM / GRU / Transformers) - Learn temporal patterns in measurement and HO histories
- Predict HO timing and target cells or beams
- Support mobility state classification
Time-series forecasting models - Predict future RSRP/RSRQ/SINR trends
- Enable proactive, rather than reactive, mobility decisions
Graph neural networks - Model relationships between cells, TRPs, and UEs
- Support cell/beam selection in dense topologies
Lightweight MLP and tree-based models - Implement mobility parameter tuning and robustness optimization
- Provide interpretable decisions for operators
Hybrid feature models - Combine location, CSI, and KPI-based features
- Improve prediction and selection performance under diverse conditions
Overall toolbox - Covers prediction, configuration, and optimization tasks
- Allows tailoring model complexity to gNB, RIC, or UE capabilities
Challenges
AI/ML-based mobility enhancement in 6G also faces several important challenges. One major issue is generalization: mobility patterns can differ substantially between cities, deployments, and frequency bands, so models trained in one environment may not transfer well to another without adaptation. Another challenge is the impact of mis-prediction; incorrect handover or reselection suggestions can lead to additional HOs, RLFs, or degraded throughput, especially for high-speed UEs. Data collection for training must respect privacy constraints while still capturing enough detail about UE trajectories and measurements. Real-time constraints also apply, since mobility-related inference often needs to run within tight timing budgets in the gNB or near-RT RIC. Finally, integration with existing mobility procedures requires clear definitions for capability signaling, fallback behavior to classical HO, and lifecycle management of mobility models.
Generalization across deployments - Mobility and traffic patterns vary widely between networks
- Models may need domain adaptation to remain effective
Risk of mis-prediction - Wrong HO or reselection decisions can cause RLFs and ping-pongs
- Requires robust fallback to classical mobility mechanisms
Data collection and privacy - Training needs detailed mobility data but must respect privacy
- May require anonymization or on-premise training approaches
Real-time inference constraints - Mobility decisions are time-critical
- Inference must fit within gNB or RIC processing budgets
Specification and lifecycle management - Need clear capability signaling and KPIs for AI-based mobility
- Must define model update, rollback, and fallback procedures
Overall complexity - AI/ML enables predictive and context-aware mobility
- But introduces new design, validation, and operational challenges
Scheduling / Resource Allocation Enhancement
In 6G, scheduling and resource allocation must orchestrate a far more complex radio environment than in 5G: extremely dense deployments, wideband carriers including FR3, massive MIMO with many layers, and diverse services ranging from eMBB to URLLC, mMTC, and new 6G-specific applications. Classical schedulers in NR are largely based on rule-based heuristics and relatively simple metrics such as CQI, buffer status, and QoS priority. These mechanisms can struggle to capture the full dynamics of interference, traffic bursts, mobility, and slice-specific policies in future 6G networks. AI/ML enables scheduling to move from fixed algorithms to learned decision-making that can adapt to traffic patterns, channel evolution, and service requirements, improving both spectral efficiency and user experience. As a result, scheduling and resource allocation enhancement is a central AI/ML use case in 6G.
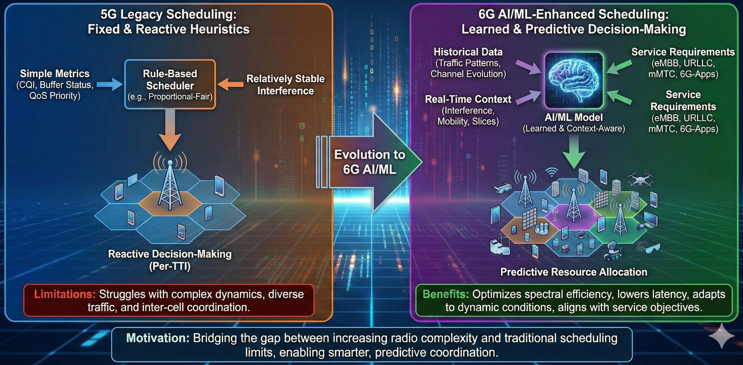
Motivation
The motivation for AI/ML-based scheduling in 6G arises from the increasing gap between the complexity of the radio environment and the expressiveness of traditional scheduling rules. Legacy schedulers typically rely on proportional-fair or similar metrics computed per TTI, assuming relatively stable interference, homogeneous traffic profiles, and limited coordination across cells or TRPs. In dense 6G deployments, interference patterns fluctuate rapidly, traffic demands vary widely across users and slices, and coordination between cells, beams, and carriers becomes more important. Fixed heuristics may fail to capture these multi-dimensional trade-offs, leading to suboptimal throughput, latency, and fairness. AI/ML can learn from historical traffic and channel data to predict near-future conditions, identify beneficial scheduling patterns, and align resource allocation with service-level objectives. This allows schedulers to become predictive and context-aware rather than purely reactive.
Classical scheduling assumes: - Simple PF-like metrics and TTI-based decisions
- Relatively stable interference and traffic patterns
- Limited coordination across cells or carriers
These assumptions break down in 6G because: - Interference and load vary quickly across time, frequency, and space
- Services have heterogeneous QoS and slice-specific policies
- Multi-cell, multi-TRP, and multi-carrier coordination is needed
As a result, heuristic schedulers may cause: - Suboptimal throughput–latency–fairness trade-offs
- Inefficient utilization of spectrum and spatial degrees of freedom
- Difficulty meeting strict URLLC or slice guarantees
AI/ML becomes attractive because it can: - Learn traffic and channel patterns from data
- Predict near-future conditions for proactive scheduling
- Map complex context to resource allocation decisions
Consequently: - 6G can achieve better spectral efficiency and QoS guarantees
- Scheduling becomes more adaptive and service-aware
Methodology
AI-based scheduling and resource allocation methods in 6G can be grouped into several categories. The first is reinforcement-learning-based (RL) scheduling, where the scheduler is modeled as an agent that selects RB, time, beam, or MCS allocations to maximize a long-term reward combining throughput, latency, and fairness. The second is supervised or imitation-learning-based scheduling, where AI models learn to mimic or improve upon expert-designed policies using historical data. A third methodology is traffic- and QoS-prediction-driven scheduling, where models forecast buffer evolution, packet arrivals, or latency deadlines and feed these predictions into otherwise conventional schedulers as enhanced inputs. Another direction is multi-cell and multi-TRP coordination, where AI/ML helps coordinate scheduling decisions across neighboring cells or TRPs to reduce interference and support joint transmission. Finally, cross-layer scheduling uses AI/ML to align MAC-level resource allocation with higher-layer objectives, such as slice SLAs, application KPIs, or energy-saving targets.
Reinforcement-learning-based scheduling - Model scheduler as an RL agent
- Use reward functions combining throughput, latency, and fairness
- Learn policies that optimize long-term performance
Supervised / imitation learning for scheduling - Train models on historical scheduling decisions and outcomes
- Mimic or refine expert heuristics
- Provide stable, low-complexity policies once trained
Prediction-driven scheduling - Predict buffer occupancy, arrivals, and deadlines
- Feed predictions to enhanced rule-based schedulers
- Enable proactive resource allocation for URLLC and eMBB
Multi-cell / multi-TRP coordination - Coordinate RB and beam allocations across cells/TRPs
- Use AI/ML to handle interference and joint-transmission decisions
Cross-layer, slice-aware scheduling - Map slice and application KPIs to MAC-level priorities
- Use AI/ML to balance per-slice guarantees and overall efficiency
Overall goal - Turn scheduling into a predictive, context-aware decision process
- Improve 6G performance across diverse services and deployments
Models
Scheduling and resource allocation tasks use a variety of AI/ML models depending on the problem formulation. For RL schedulers, deep Q-networks (DQN), policy-gradient methods, and actor–critic architectures such as DDPG, PPO, or A3C are commonly considered. For supervised and imitation learning, MLPs and gradient-boosted trees are often used due to their balance between accuracy and interpretability. Time-series models such as LSTM, GRU, and temporal convolutional networks (TCN) are applied for traffic and QoS prediction. Graph neural networks (GNNs) can represent multi-cell topologies and interference relationships, enabling coordinated scheduling across cells and TRPs. Lightweight models may be deployed in near-RT RIC or gNB for fast inference, while more complex models can run in non-RT RIC to generate policies or configuration parameters offline.
Deep RL models (DQN, PPO, actor–critic) - Learn scheduling policies through interaction with simulated or real environments
- Handle complex, high-dimensional state spaces
MLP and tree-based models - Used for supervised or imitation-learning-based schedulers
- Provide interpretable and relatively lightweight policies
Time-series models (LSTM / GRU / TCN) - Predict traffic, buffer, and QoS evolution
- Provide inputs for prediction-driven scheduling
Graph neural networks - Represent multi-cell interference and topology
- Support coordinated scheduling across cells and TRPs
Overall toolbox - Covers policy learning, prediction, and coordination tasks
- Allows splitting complexity between gNB, near-RT RIC, and non-RT RIC
Challenges
AI/ML-based scheduling in 6G introduces several challenges. First, stability and fairness are critical: small changes in scheduling policy can significantly impact user experience, so learned policies must be carefully validated before deployment. Second, obtaining representative training data for RL or supervised learning is difficult, especially for rare events or extreme load conditions. Third, real-time constraints at the gNB or near-RT RIC limit the complexity and inference time of deployed models. Fourth, explainability is important for operators, who must understand why certain scheduling decisions are made, particularly when SLAs or regulatory constraints are involved. Finally, integrating AI-based schedules with existing NR/6G MAC procedures and standardization frameworks requires clear definitions for capability signaling, policy updates, and fallback to classical schedulers when needed.
Stability and fairness - Scheduling policies directly affect user QoS
- Learned policies must avoid starvation and instability
Training data and rare events - Need data covering high-load and edge cases
- Simulation-to-reality gaps can degrade performance
Real-time inference constraints - Scheduling decisions must be made within tight timing budgets
- Limits model size and complexity at runtime
Explainability and operator trust - Operators need insight into AI scheduling behavior
- Helps with troubleshooting and SLA verification
Standardization and integration - Need clear frameworks for deploying AI-based schedulers
- Must define capability signaling, policy updates, and fallback mechanisms
Overall complexity - AI/ML offers powerful scheduling improvements
- But increases design, validation, and operational complexity
Power Amplifier (PA) Enhancement
In 6G, power amplifier (PA) enhancement becomes critical because radio units must handle much wider bandwidths, higher peak-to-average power ratios (PAPR), higher-order modulation, and large antenna arrays while still meeting tight spectral-emission and efficiency requirements. Traditional PA design and digital predistortion (DPD) techniques were developed mainly for single-carrier or limited-bandwidth OFDM scenarios, with relatively simple behavioral models and fixed adaptation loops. As 6G moves into upper-mid bands and FR3, uses larger aggregated bandwidths, and deploys many power amplifiers in massive-MIMO arrays, classical DPD solutions can become too complex, too power-hungry, or insufficiently accurate. At the same time, operators are under pressure to improve energy efficiency and reduce the cost per bit, which requires operating PAs closer to saturation without violating linearity and spectral-mask requirements. AI/ML provides new ways to learn PA characteristics, compensate nonlinearities, and co-design waveform and PA behavior, enabling 6G systems to push the efficiency–linearity trade-off further than conventional methods.
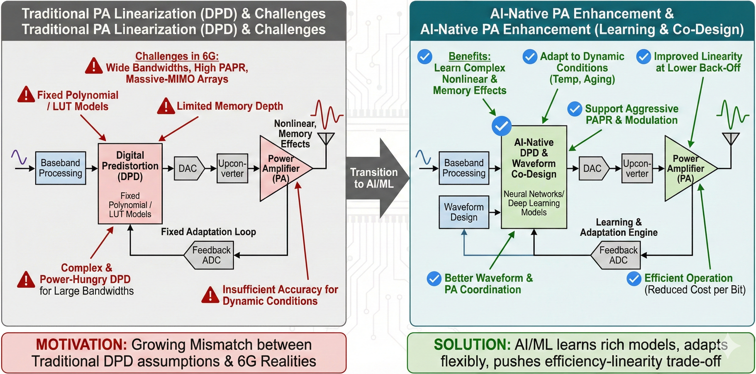
Motivation
The motivation for applying AI/ML to PA enhancement in 6G arises from the growing mismatch between traditional DPD assumptions and the realities of wideband, multi-antenna transmitters. Classical PA linearization methods often rely on polynomial or lookup-table models with limited memory depth, tuned for relatively narrowband operation and slowly varying conditions. In 6G, PAs must cope with very wide instantaneous bandwidths, carrier aggregation, dynamic spectrum use, and a larger range of operating points as traffic and beam patterns evolve. This increases both the dimensionality and variability of the nonlinearity to be compensated. Moreover, massive-MIMO and distributed RU deployments multiply the number of PAs, making per-PA calibration and adaptation difficult with purely hand-crafted models. AI/ML can learn rich nonlinear input–output relationships with memory effects, capture temperature and aging behavior, and adapt more flexibly to changing conditions. This enables improved linearity at lower back-off, support for more aggressive PAPR and modulation schemes, and better coordination between waveform design and PA operation.
Traditional PA and DPD design assumes: - Polynomial or LUT-based behavioral models with limited memory
- Relatively narrow bandwidths and slowly varying operating points
- Per-PA calibration done infrequently and offline
These assumptions are stressed in 6G because: - Instantaneous bandwidths and carrier aggregation widths increase
- PAPR grows with high-order modulation and wideband OFDM
- Massive-MIMO and multi-RU deployments multiply the number of PAs
- Operating points change dynamically with traffic and beamforming
Classical approaches under these conditions lead to: - Excessive back-off to satisfy linearity, reducing efficiency
- Exploding complexity in wideband DPD models
- Difficulty maintaining spectral-mask compliance across PAs
AI/ML becomes attractive because it can: - Learn rich nonlinear PA behavior with memory effects
- Adapt models to temperature, aging, and operating-point changes
- Co-optimize waveform and PA operation for better efficiency–linearity trade-offs
Consequently: - 6G can operate PAs closer to saturation while meeting EVM and ACLR targets
- Wideband and multi-antenna transmitters become more power-efficient
Methodology
PA enhancement with AI/ML in 6G can be organized into several main methodologies. The first is AI-based PA behavioral modeling, where neural networks learn the nonlinear, memory-dependent mapping from baseband input to RF output across different operating conditions. These models can then be used either directly in DPD design or as references for online adaptation. The second methodology is AI-based digital predistortion, in which the predistorter itself is implemented as a neural network that is trained to invert the PA response and minimize distortion at the antenna port. A third methodology is PAPR- and waveform-aware optimization, where AI/ML helps design or select waveforms and shaping parameters that are more PA-friendly while meeting spectral and performance constraints. A fourth direction is PA health and aging monitoring, using models to detect drift, degradation, or anomalies in PA behavior and trigger recalibration or maintenance. Finally, AI can support coordination across multiple PAs in massive-MIMO arrays, learning joint relationships that affect overall beam quality and out-of-band emissions.
AI-based PA behavioral modeling - Learn the nonlinear input–output mapping with memory
- Model dependence on bias, temperature, and frequency
- Provide accurate references for DPD and system design
Neural-network-based digital predistortion - Implement DPD as a trainable neural mapping
- Invert PA behavior to improve linearity at the antenna
- Adapt to operating conditions with online updates
PAPR- and waveform-aware optimization - Use AI/ML to design PA-friendly waveforms and shaping
- Balance spectral regrowth, EVM, and efficiency
- Enable more aggressive modulation under PA constraints
PA health and aging monitoring - Monitor changes in PA characteristics over time
- Detect drift, faults, or degradation using learned models
- Trigger recalibration or maintenance proactively
Multi-PA and array-level coordination - Learn joint effects across PAs in massive-MIMO arrays
- Control array-level ACLR and beam distortion
Overall goal - Improve PA efficiency while preserving or improving linearity
- Support wideband, high-order modulation in 6G RUs
Models
Various neural architectures can be applied to PA enhancement, each suited to different aspects of the problem. Feedforward MLPs and deep fully connected networks are commonly used for static or mildly dynamic nonlinear mappings. For PAs with significant memory effects, temporal models such as tapped-delay MLPs, temporal CNNs, or recurrent networks (LSTM, GRU) can better capture the dependence on past samples. Volterra-inspired neural structures or basis-function networks can approximate classic PA models while adding learning flexibility. CNNs can also be used when modeling wideband signals in the time–frequency domain. For multi-PA and array-level coordination, graph neural networks may be employed to represent the coupling between PAs and the spatial structure of the array. In all cases, model complexity must be chosen carefully to fit within the real-time constraints of baseband processing.
Feedforward MLP and deep fully connected networks - Model static or quasi-static nonlinear PA behavior
- Suitable for lower-memory or narrowband cases
Temporal models (tapped-delay MLP, temporal CNN, LSTM/GRU) - Capture memory effects and dynamic behavior
- Improve modeling accuracy for wideband PAs
Volterra-inspired and basis-function networks - Blend classical PA modeling with learning flexibility
- Provide structured approximations with fewer parameters
CNN-based time–frequency models - Process wideband signals in spectrogram-like representations
- Enable joint consideration of in-band and out-of-band behavior
Graph neural networks for array-level effects - Model interactions across many PAs in massive-MIMO arrays
- Support coordinated control for ACLR and beam integrity
Overall toolbox - Supports detailed PA modeling, DPD, and array coordination
- Allows tuning of complexity to RU hardware capabilities
Challenges
AI/ML-based PA enhancement in 6G also faces important challenges. One central issue is the need for very high reliability: PA linearization errors directly affect spectral compliance and can cause interference beyond the licensed band, so any learned model must be robust and thoroughly validated. Another challenge is the scarcity and cost of high-quality training data, since collecting accurate PA input–output pairs across operating conditions, temperatures, and aging states can be time-consuming and hardware-intensive. Complexity and latency constraints in the RU and baseband limit the size and depth of deployable models, particularly for per-sample DPD processing. Generalization across manufacturing variations, frequency bands, and deployment environments is also non-trivial: models trained on one PA or batch may not work optimally on another without adaptation. Finally, integrating AI-based PA control into standardization and RAN4 testing requires clear procedures for model validation, performance guarantees, and fallback to conventional DPD schemes when needed.
Reliability and spectral compliance - Errors in PA models or DPD can violate spectral masks
- Requires robust, well-tested models before deployment
Training data collection - Need extensive PA measurements across conditions
- Data collection is time- and resource-intensive
Complexity and latency constraints - Per-sample DPD must run under strict timing budgets
- Limits the depth and size of neural architectures
Generalization and adaptation - Models must handle process variation, temperature, and aging
- May require online adaptation or per-unit fine-tuning
Standardization and testing - Need frameworks for validating AI-based PA solutions
- Must ensure interoperability and safe fallback to classical DPD
Overall complexity - AI/ML opens new possibilities for PA efficiency and linearity
- But increases design, validation, and operational complexity
Modulation / Demodulation Enhancement
In 6G, modulation and demodulation design must support higher spectral efficiency, wider bandwidths, and more challenging channel conditions than 5G. Traditional QAM-based constellations and linear demodulators struggle under FR3 impairments, low-SNR operation, non-linear PA effects, and mixed numerologies. AI/ML provides new ways to design, adapt, and decode modulation schemes by learning directly from channel conditions and hardware characteristics. This enables improved robustness, efficient high-order modulation, and non-conventional constellation shaping suitable for future 6G deployments.
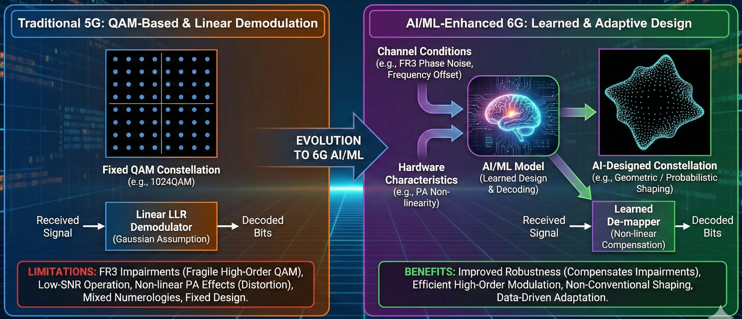
Motivation
The main motivation for AI/ML-based modulation and demodulation enhancement in 6G comes from the growing mismatch between classical QAM designs and real-world 6G operating environments. High-order QAM constellations (e.g., 1024QAM, 4096QAM) become extremely fragile under FR3 phase noise, frequency offset, and PA non-linearity. Traditional LLR demodulators assume linear Gaussian channels and cannot exploit the true statistics of hardware impairments or non-linear distortion. Furthermore, probabilistic and geometric shaping require optimized constellation distributions that are difficult to design analytically. AI/ML provides a data-driven pathway to design constellations, learn demappers, and compensate complex impairments that classical analytical methods cannot handle effectively.
Classical QAM demodulation assumes: - Linear Gaussian channel behavior
- Static, analytically designed constellation points
- Predictable PA and RF impairments
In 6G these assumptions break down due to: - High-order QAM sensitivity to phase noise and CFO
- Wideband PA non-linearity and spectral regrowth
- FR3 mobility, frequency-selectivity, and Doppler
Consequences include: - Large EVM degradation for high-order QAM
- Inaccurate LLRs under non-ideal hardware
- Difficulty scaling modulation to higher SE
AI/ML becomes necessary because it can: - Learn constellations robust to impairments
- Compensate RF/PA distortions in the demapper
- Optimize probabilistic and geometric shaping
Thus enabling: - Higher effective modulation orders in 6G
- Improved demodulation reliability under FR3
Methodology
AI/ML-based modulation and demodulation enhancements can be categorized into several methodologies. The first is learned geometric shaping, where neural models optimize constellation point positions for robustness and capacity. The second is probabilistic shaping with AI-based distribution learning, improving shaping gain by matching symbol distributions to channel statistics. Another methodology is learned demapping, where neural demodulators replace or augment LLR computation using channel-aware and hardware- aware models. A fourth methodology is joint optimization of modulation with PA/DPD models, enabling constellations tailored to transmitter non-linearity. Finally, end-to- end learning frameworks treat modulation/demodulation as part of an autoencoder system, enabling jointly optimized symbol designs.
Learned geometric shaping - Neural optimization of constellation point placement
- Improved robustness to phase noise and non-linearity
- Higher SNR efficiency than fixed QAM
AI-optimized probabilistic shaping - Learn symbol probability distributions
- Adapt distribution to channel SNR and impairments
- Supports rate-flexible shaping strategies
Neural demodulators / learned LLR - Replace classical LLR with neural inference
- Handle non-Gaussian noise and RF distortion
- Improve decoding reliability for high-order QAM
Waveform–PA joint optimization - Learn constellations considering PA/DPD models
- Reduce PA back-off and spectral regrowth
- Enable high-order modulation under practical RUs
End-to-end autoencoder-based modulation - Treat modulation and demodulation as encoder–decoder
- Jointly optimize constellation, mapping, and receiver
- Support non-classical symbol designs
Overall goal - Increase spectral efficiency
- Improve demodulation robustness under 6G impairments
Models
Several model classes are used in AI-based modulation and demodulation. MLP-based models are commonly used for geometric shaping and simple neural demappers. CNNs and attention-based architectures help process time–frequency features for demodulation under distortion. Variational autoencoders (VAEs) and latent-space models help design structured constellations. End-to-end autoencoders combine encoders (modulation) and decoders (demodulation) with a channel layer. Lightweight models are needed for UE-side demodulation under tight complexity constraints.
MLP models - Used for neural demappers and geometric shaping
CNN / time–frequency models - Support demodulation under RF/PA distortion
Transformer-based demodulators - Capture long-range dependencies in symbol sequences
Variational autoencoders - Produce structured latent-space constellations
End-to-end autoencoders - Jointly learn modulation and demodulation
Overall toolbox - Supports modulation design, shaping, and robust demodulation
Challenges
AI-based modulation and demodulation introduce several challenges. First, constellation design and neural demodulation must remain interpretable and meet strict RAN4 performance requirements for EVM, ACLR, and BER. Second, learned constellations must generalize across SNRs, channels, and hardware variations. Third, complexity constraints at the UE side limit the size of deployable demodulators. Fourth, integrating learned constellations into standardized bit-mapping and rate-matching procedures requires careful design. Finally, two-sided learning may require LCM procedures for updating transmitter/receiver models.
Standardization constraints - Must meet EVM/ACLR limits and fit into existing 3GPP structures
Generalization issues - Models must work across SNRs, channels, and hardware
UE complexity limits - Demodulation must run within tight power/latency budgets
Interoperability and LCM - Two-sided models require coordinated updates
Overall complexity - AI enables powerful shaping and decoding, but complicates validation
Reference
- RAN1#122 (2025-08-25 - Bengaluru(IN))
- R1-2506456 — Moderator summary #2 on AI/ML for 6GR — Samsung (Moderator)
- R1-2506455 — Moderator summary #1 on AI/ML for 6GR — Samsung (Moderator)
- R1-2506384 — New use case for AI/ML in 6GR interface — Pengcheng Laboratory
- R1-2506364 — AI/ML in 6GR Interface — CEWiT, Tejas Network
- R1-2506345 — Discussion on AI/ML in 6GR - Physical Layer — Rakuten Mobile, Inc
- R1-2506314 — Discussion on AI/ML in 6GR Interface — IIT Madras, IIT Kanpur, CEWiT
- R1-2506262 — Views on 6G AI-native System Design — CAICT
- R1-2506250 — Discussions on AI/ML in 6GR interface — Sharp
- R1-2506243 — Views on AI/ML in 6GR Air Interface — DeepSig
- R1-2506223 — AI/ML in 6GR air interface — Qualcomm Incorporated
- R1-2505970 — Discussion on AI/ML in 6GR — Fujitsu
- R1-2505932 — Discussion on AI/ML in 6GR interface — NEC
- R1-2505920 — AI/ML Use Cases for 6GR — BOOST Mobile Network
- R1-2505918 — On AI/ML for 6G air interface — Apple Inc
- R1-2505828 — AI/ML for 6G Air Interface — InterDigital, Inc.
- R1-2505823 — Discussion on AI/ML in 6GR interface — LG Electronics
- R1-2505805 — AI/ML Use Cases for 6G — National Taiwan University
- R1-2505786 — Discussion on AI/ML in 6GR interface — Panasonic
- R1-2505782 — AI/ML in 6GR interface — Lekha Wireless Solutions
- R1-2505762 — AI/ML use cases for 6GR air interface — OPPO
- R1-2505701 — Discussion on inter-vendor training collaboration for two-sided AI/ML models — Panasonic
- R1-2505690 — AI/ML in 6GR — Lenovo
- R1-2505686 — AI/ML in 6GR interface — Tejas Networks Ltd, CEWiT, IISC Bangalore, IITM, IIT Kanpur
- R1-2505678 — Initial Views on AI/ML in 6GR interface — Ofinno
- R1-2505592 — AI and ML in 6GR air interface — NVIDIA
- R1-2505588 — AI/ML Use cases and framework for 6GR — Samsung
- R1-2505495 — Discussion on AI-based Smart Radio for 6G Air Interface — ZTE Corporation, Sanechips
- R1-2505482 — Discussion on AI/ML in 6GR air interface — TCL
- R1-2505468 — Initial consideration on AI/ML in 6GR interface — Xiaomi
- R1-2505421 — Discussion on AI/ML in 6GR interface — vivo
- R1-2505266 — AI/ML of 6GR Air Interface — Google
- R1-2505188 — Views on AI/ML in 6GR air interface — Huawei, HiSilicon
- R1-2505180 — AI/ML Use Cases for 6GR Air Interface — Ericsson
- R1-2505177 — Discussion on AI/ML in 6GR interface — Spreadtrum, UNISOC
- R1-2505157 — AI/ML in 6GR interface — Kyocera
- R1-2505147 — Discussion on AI/ML in 6GR interface — FUTUREWEI
- R1-2505132 — Views on AI/ML Operation and Use Cases for 6G Radio Air Interface — Nokia
- RAN1#123 (2025-11-17 - Dallas(US)
- R1-2508324 — Discussion on AI/ML in 6GR interface — FUTUREWEI
- R1-2508341 — Views on AI/ML Operation and Use Cases for 6G Radio Air Interface — Nokia
- R1-2508351 — Discussion on AI/ML-driven use cases for 6GR — BJTU
- R1-2508365 — AI/ML Use Cases for 6GR Air Interface — Ericsson
- R1-2508366 — AI/ML in 6GR interface — Kyocera
- R1-2508392 — Discussion on AIML in 6GR interface — Spreadtrum, UNISOC
- R1-2508396 — Other aspects of AIML for CSI compression — Ericsson
- R1-2508437 — Discussion on AI/ML in 6GR interface — vivo
- R1-2508460 — Discussion on AI/ML in 6GR interface — CMCC
- R1-2508515 — AI/ML for 6G Air Interface — InterDigital, Inc.
- R1-2508539 — Discussion on AI/ML in 6GR air interface — TCL
- R1-2508549 — Discussion on AIML in 6GR interface — NEC
- R1-2508582 — AI/ML in 6GR interface — CATT, CICTCI
- R1-2508643 — AI/ML use cases and framework for 6GR Air Interface — AT&T
- R1-2508689 — Discussion on AI/ML in 6GR interface — Xiaomi
- R1-2508697 — Discussion on AI-based Smart Radio for 6G Air Interface — ZTE Corporation, Sanechips
- R1-2508732 — AIML use cases for 6GR air interface — OPPO
- R1-2508740 — Views on AI/ML in 6GR air interface — Huawei, HiSilicon
- R1-2508807 — AI/ML Use cases and framework for 6GR — Samsung
- R1-2508808 — Moderator summary #1 on AI/ML for 6GR — Moderator (Samsung)
- R1-2508809 — Moderator summary #2 on AI/ML for 6GR — Moderator (Samsung)
- R1-2508810 — Moderator summary #3 on AI/ML for 6GR — Moderator (Samsung)
- R1-2508811 — Moderator summary #4 on AI/ML for 6GR — Moderator (Samsung)
- R1-2508827 — AI/ML Use Cases for 6G RAN — Tejas Network Limited
- R1-2508916 — Discussion on AI/ML in 6GR interface — Lekha Wireless Solutions
- R1-2508933 — Discussion on AI/ML in 6GR — Fujitsu
- R1-2508947 — AI/ML in 6GR Air Interface — Google
- R1-2508978 — Discussion on AI/ML in 6GR interface — ETRI
- R1-2508999 — Discussion on AI/ML in 6GR interface — Panasonic
- R1-2509004 — AI/ML in 6GR — Lenovo
- R1-2509008 — AIML in 6GR air interface — KAIST
- R1-2509021 — AI and ML in 6GR air interface — NVIDIA
- R1-2509022 — Discussion on AI/ML in 6GR — IMU
- R1-2509039 — Views on AI/ML in 6GR interface — Ofinno
- R1-2509046 — Discussion on AI ML in 6GR air interface — Hanbat National University
- R1-2509050 — Discussion on AI/ML for 6GR interface — Ruijie Networks Co. Ltd
- R1-2509078 — Use cases for AI/ML in 6GR Interface — Sony
- R1-2509115 — On AI/ML for 6G air interface — Apple
- R1-2509116 — Discussion on AI/ML in 6GR interface — AUMOVIO
- R1-2509148 — AI/ML in 6GR Air Interface — MediaTek Inc.
- R1-2509184 — Discussions on AI/ML in 6GR interface — Sharp
- R1-2509236 — AI/ML in 6GR air interface — Qualcomm Incorporated
- R1-2509251 — Discussion on AI/ML in 6GR interface — Transsion Holdings
- R1-2509287 — Discussion on AI/ML for 6GR air interface — NTT DOCOMO, INC.
- R1-2509302 — Use cases for AI/ML in 6GR interface — KT Corp.
- R1-2509354 — AI/ML in 6GR Interface — CEWiT
- R1-2509373 — Discussion on AI/ML in 6GR Interface — Indian Institute of Tech (M)
- R1-2509411 — Discussion on AI/ML-enabled use cases for 6GR — BUPT, ZGC Institute of Ubiquitous-X Innovation and Application
- R1-2509417 — New use cases for AI/ML in 6GR interface — Pengcheng Laboratory, ZGC Institute of Ubiquitous-X Innovation and Application
- R1-2509516 — AI/ML Use cases and framework for 6GR — Samsung